Updates on the Nixpkgs security tracker
We’ve reached the Github login and manual record linkage milestone end of August. As of today, delivery of the project is late by another 4 months, after the last plan for being late by 8 months. It’s a disappointing result – many reasons, no excuses.
I’m back to it now and take budget responsibility and full accountability for getting the system into a state that is usable by the security team by Friday 2024-12-13. Which means that if you have questions, ask me directly. I allocated at least 5 hours per week on active planning and direction.
Ping me if you want to join the private Matrix room for beta testing, where we already collected some initial feedback from people involved in Nixpkgs security.
@erictapen will work full time on designing and building the user interface for the planned workflows. @raitobezarius will improve the performance of the data ingestion and processing pipeline, @proofconstruction will support us with backend-related tasks, both a couple of hours per week, with assistance from @alejandrosame as needed. @Erethon will latch onto the NixOS infrastructure team to ensure we have the service deployed to nixos.org for demo day.
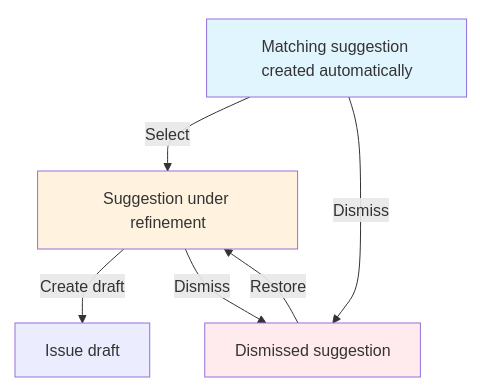
This week we have refined the user interactions to a degree where we can break down the implementation requirements into manageable chunks. The general idea is that a vulnerability record goes through three phases:
-
Initial triaging
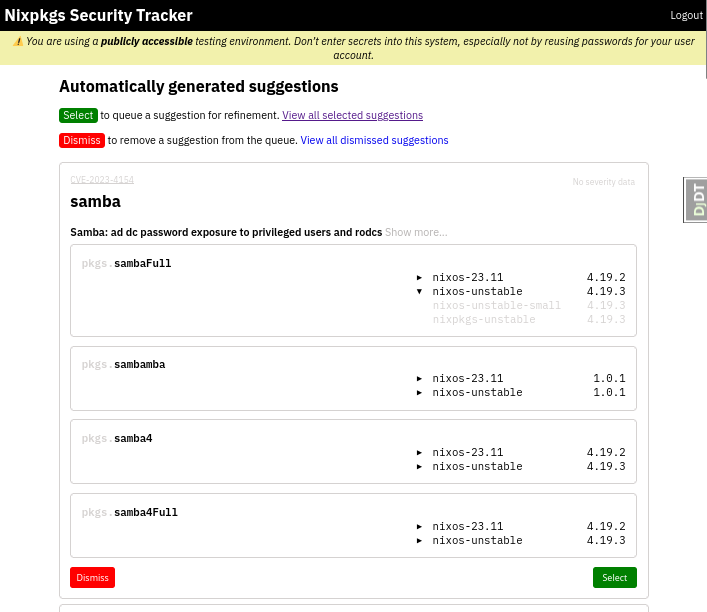
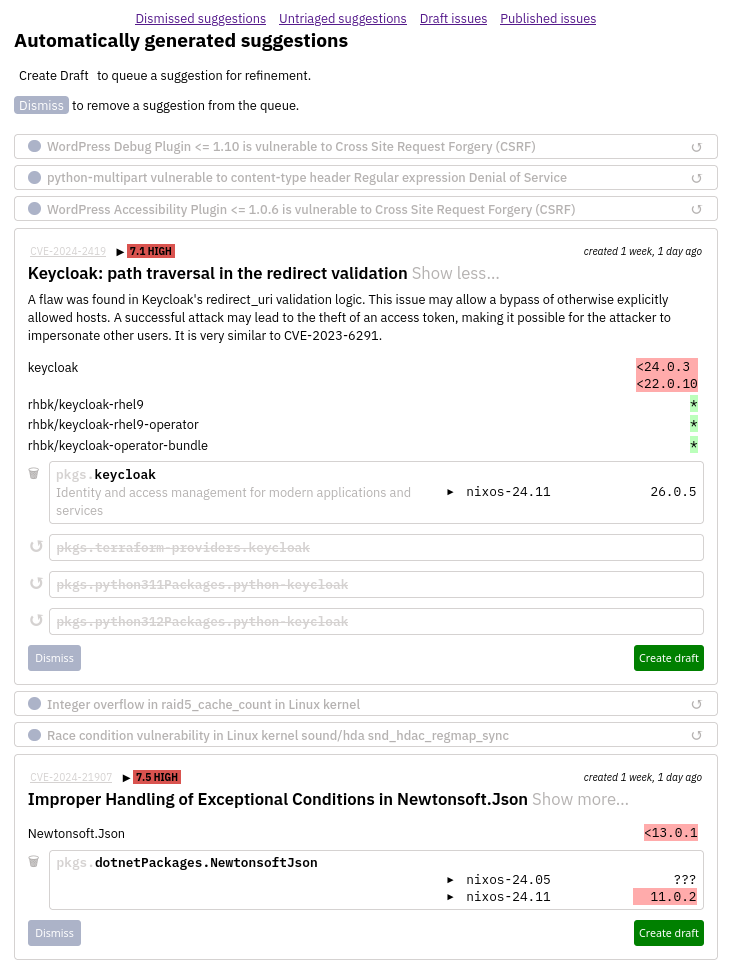
Security team members get presented with a queue of pre-computed suggestions for matching CVEs to Nixpkgs derivations, which they would filter for things to inspect further. We already have most data to do a decent automatic matching, but it needs to be validated by humans, and we expect most of it to be thrown away. The aspirational goal is to make it convenient enough to ultimately reach “inbox zero”.
-
Draft
An automatic match will never be perfect, so a record needs to be adjusted. Many CVEs we get have duplicates, the contained information is often coarse or ambiguous, so the security team will have to check and possibly correct which derivations it applies to before publishing the record.
-
Mitigation
Once a draft is ready, it should be published as a GitHub issue where all affected maintainers are pinged. The usual workflow continues from there. Once the issue is closed, the vulnerability record is archived automatically.
You can follow progress in the milestones on GitHub.
We have a bunch of obvious refinements for these workflows in the backlog, such as smoother, structured searching and filtering for CVEs and derivations, and periodic notifications for security team members and maintainers, but those are currently not prioritised. We’ll focus on enabling the essential user stories for now.
On using GitHub dependency submissions
@sambacha Thanks for the pointer. I’ve investigated the possibility of offloading advisory handling to GitHub, and doing that can be at best considered future work.
There exist GitHub - tweag/genealogos: Genealogos, a Nix sbom generator · GitHub (@ErinvanderVeen) and GitHub - tweag/nixtract: A CLI tool to extract the graph of derivations from a Nix flake. · GitHub (@Arsleust) to generate dependency information that could be consumed by GitHub, but those can’t be used at Nixpkgs scale. The security tracker currently periodically evaluates all tracked channel branches and puts everything in a database. We could construct SBOMs or any required format from there and submit it within rate limits, but that’s essentially a different project altogether.
And then we’d still have an by far inferior UX to address advisories which, most importantly, doesn’t take into account how Nixpkgs is currently developed. This project is to serve the security team and package maintainers, and GitHub simply doesn’t support our current needs.
Last but not least, there are good reasons to keep our dependency to GitHub limited. Both STF and NGI are interested in us (and everyone else) adopting free and open source software for all workflows. Control over the supply chain is part of supply chain security.