I just want to note multiple things regarding that.
I very much agree that this data is extremely valuable, and losing it would be a terrible blow for research communities and even understanding our own ecosystems.
That’s why I believe, no matter what happens: new store paths should be shipped to something that does not cost egress fees if possible, more on that later.
Onto the next thing:
The $32K migration fee, is, I assume, the egress thingie that AWS charge everyone for trying to quit their platform.
Multiple things to unpack:
(1) Have we reached out to AWS regarding this matter while pleading our case as a non-trivial open source project (which they benefited from, I’m certain, indirectly)?
(2) Have we reached out to a financial cloud experts such as https://www.duckbillgroup.com/ which are very active on social medias and I usually believe nice to open source projects for help?
(3) Egress fees are a known tactic to vendor lock-in people into a platform:
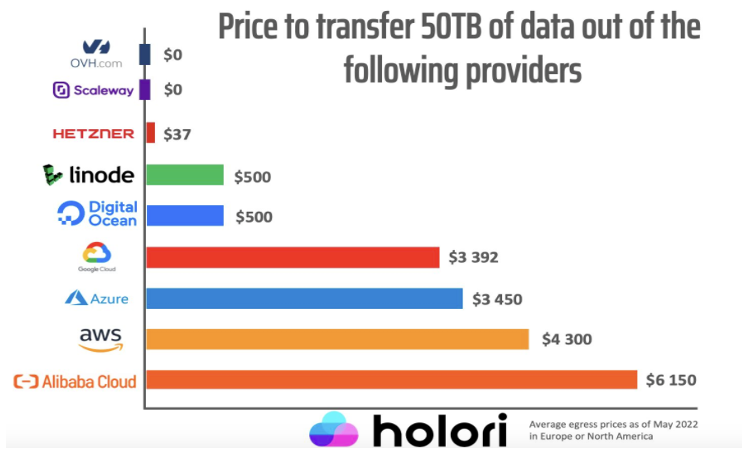
AWS are a very well-known offender on that.
Thankfully, R2 Object Storage has ZERO egress fee for now.
I think this situation is highly changing with respect to regulations:
https://twitter.com/platombe/status/1656634228979781633 (French tweet on a law attacking the egress fees situation from the cloud providers by the French government).
Sécuriser et réguler l'espace numérique (art. 7. §. 6)
« III. – Il est interdit à tout fournisseur de services d’informatique en nuage de facturer, dans le cadre des contrats qu’il conclut avec une personne exerçant des activités de production, de distribution ou de services, des frais au titre du transfert de données vers les infrastructures de cette personne ou vers celles mises à disposition, directement ou indirectement, par un autre fournisseur, à l’exception des frais de migration liés au changement de fournisseur.
“III. – It is prohibited for any provider of cloud computing services to charge, within the framework of the contracts it concludes with a person carrying out production, distribution or service activities, fees for the transfer of data to infrastructure of this person or to those made available, directly or indirectly, by another supplier, with the exception of migration costs related to the change of supplier.
— Google Translate, 2023
I believe that this could apply enough pressure so that AWS could yield this stupid amount of fees in our special case, at least, this would be a gesture of goodwill given the thin ice they are on.
– Of course, nothing is magic, and it could be as well that all those attempts would fail. I just want to make sure that we attempt everything and that our failed attempts will also serve as examples for further leveling the playing field for those migrations, which we are definitely not the only ones to do.
On long-term solutions
The breakdown shows:
- 107 TiB in standard storage
- 318 TiB in infrequent access storage
for a total of 425 TiB.
Current technology gives us at reasonable prices: 30.72TB SSD (e.g. PM1643a) and 22TB HDD.
Assuming we store 150TB of “hot storage” with a fast medium (SSD): 10 professional disks of 15.36TB. (no redundancy is assumed here.) for a cost of ~11K EUR.
Assuming we store 500TB of “cold storage” with a slow medium (HDD): 23 professional disks of 22TB. (no redundancy is assumed here.) for a cost of ~13.8K EUR.
What did we miss in this small computation?
- Geodistribution? We don’t seem to care because we have (for now?) Fastly in front of it which will geodistribute the cache across the world? (Also, we have the back’n’forth situation latency between the US and EU for some current servers of the infrastructure.)
- Internet? I can speak for France easily and having 100Gbps or even 400Gbps and being plugged directly in the adequate IXP is not really complicated, I can even email get a proper quote on what it would cost. Last time I checked, having something like 10Gbps commit (it means that you get 95th percentile 10Gbps guaranteed) was around 1-2K EUR per month.
- Disk replacement? Yes! I didn’t conduct the long term analysis and I wanted to post this early. This should be computed and included in the price by using Backblaze B2 statistics for example (Backblaze Drive Stats: Download Hard Drive Reliability Stats, Reports, and Test Data).
- Human cost? Yes! This all relies on under the assumption we will have enough persons to handle such a thing and operate it correctly. Is this a fair assumption? Let’s see below.
- Durability? Yes! Amazon S3 provides an insane durability metric, which is cool and neat: though, do we need it? (99.999999999% of durability FWIW, yes, it has this much 9s. But only 99.99% availability) — though, we can push our metric further by piling up on redundancy and multiple tiered solutions as we wish.
- You say it: I could have forgotten something in this.

This small exercise is important IMHO to decide properly for the next solution following the rule “never let a good crisis go to waste”.
NixOS’s cache has specific properties that are not shared by all users of Amazon S3 and we don’t need to stay captive in a cloud ecosystem if we don’t need to.
While I don’t think it’s realistic except if enough people step in, and it ultimately becomes realistic to provide a homemade solution for this (be it through something like a Ceph filesystem or Garage object storage or MinIO object storage or ). I feel like this has shown the need for our community to step in for those things, as we definitely have the expertise in-house and the scale for it.
My proposal would probably say: let’s try to experiment on those things I said before. For the human cost, as this is an experimentation, it should not have detrimental impacts. An alternative is to consider scaling the infrastructure team adequately and give them more power regarding this. It’s also a unique position to do something about the signing key of the store (see latest RFC on the subject for more information).
Finally, while I am not super fond of this solution, have we considered university mirrors like many other distributions do it and have we considered working with them towards that?
Anyway, I hope that my messy “chime-in” can provide new leads on what we can do regarding this situation. I would find extremely regrettable:
(1) we lose the historical data because AWS egress fees are enormous, have we considered using AWS Snowmobile? Or similar “physical transfer” solutions to ship them out?
(2) we would waste the money of the Foundation on a non-stable situation which would cost us more on the long run because we just get milked by cloud providers who have insane margins because IMHO the tradeoff for using them is skill/competency/time/human cost — nixpkgs is full of that! Let’s make it shine.