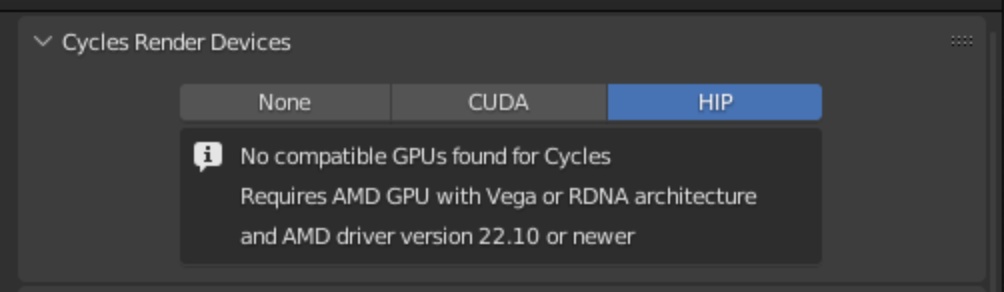
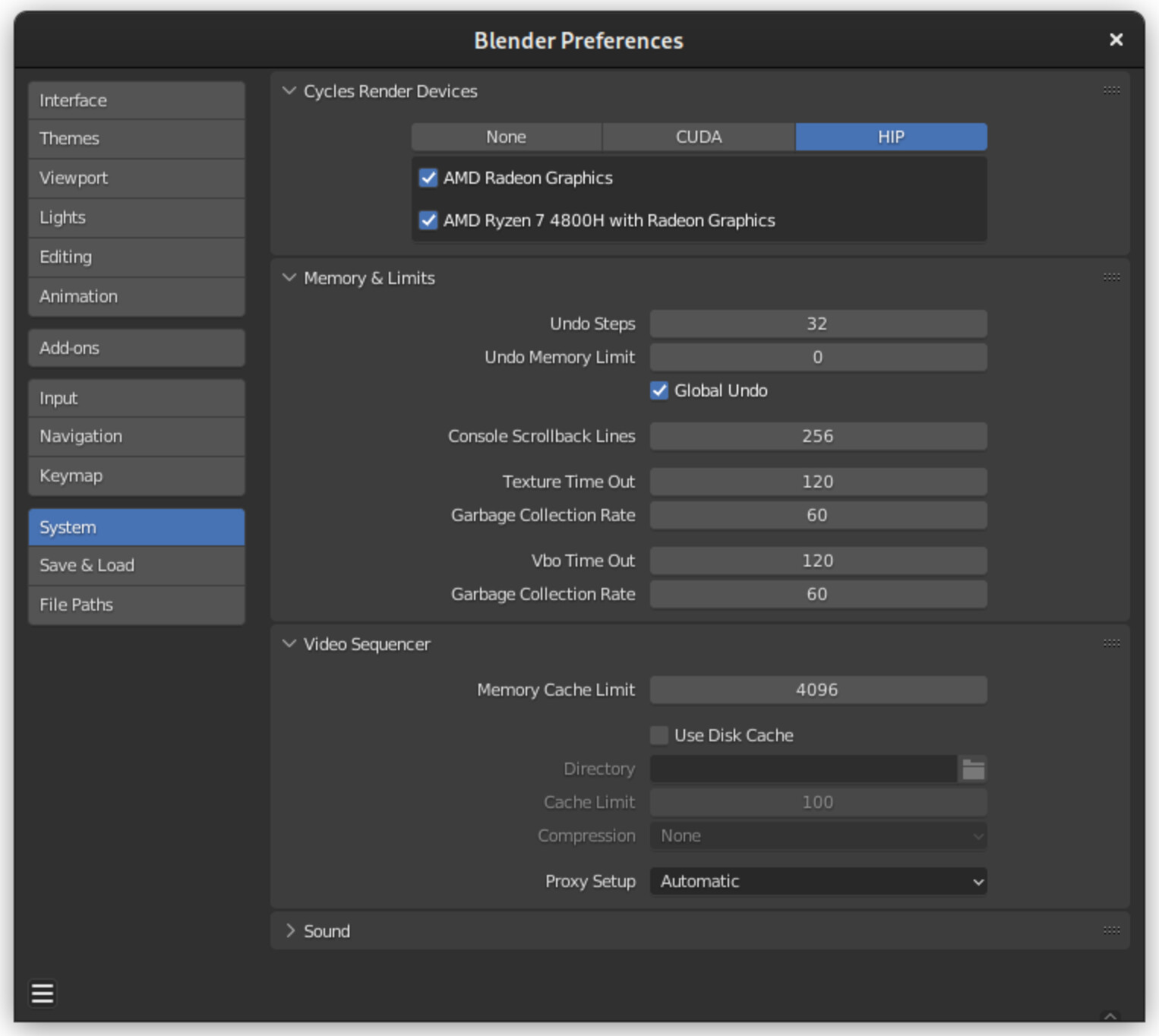
I have trouble getting GPU acceleration in Blender 3.1 with Cycles and would very much appreciate help.
I believe to get it Blender needs to use HIP API. At the moment the system preferences in Blender don’t show HIP as an option.
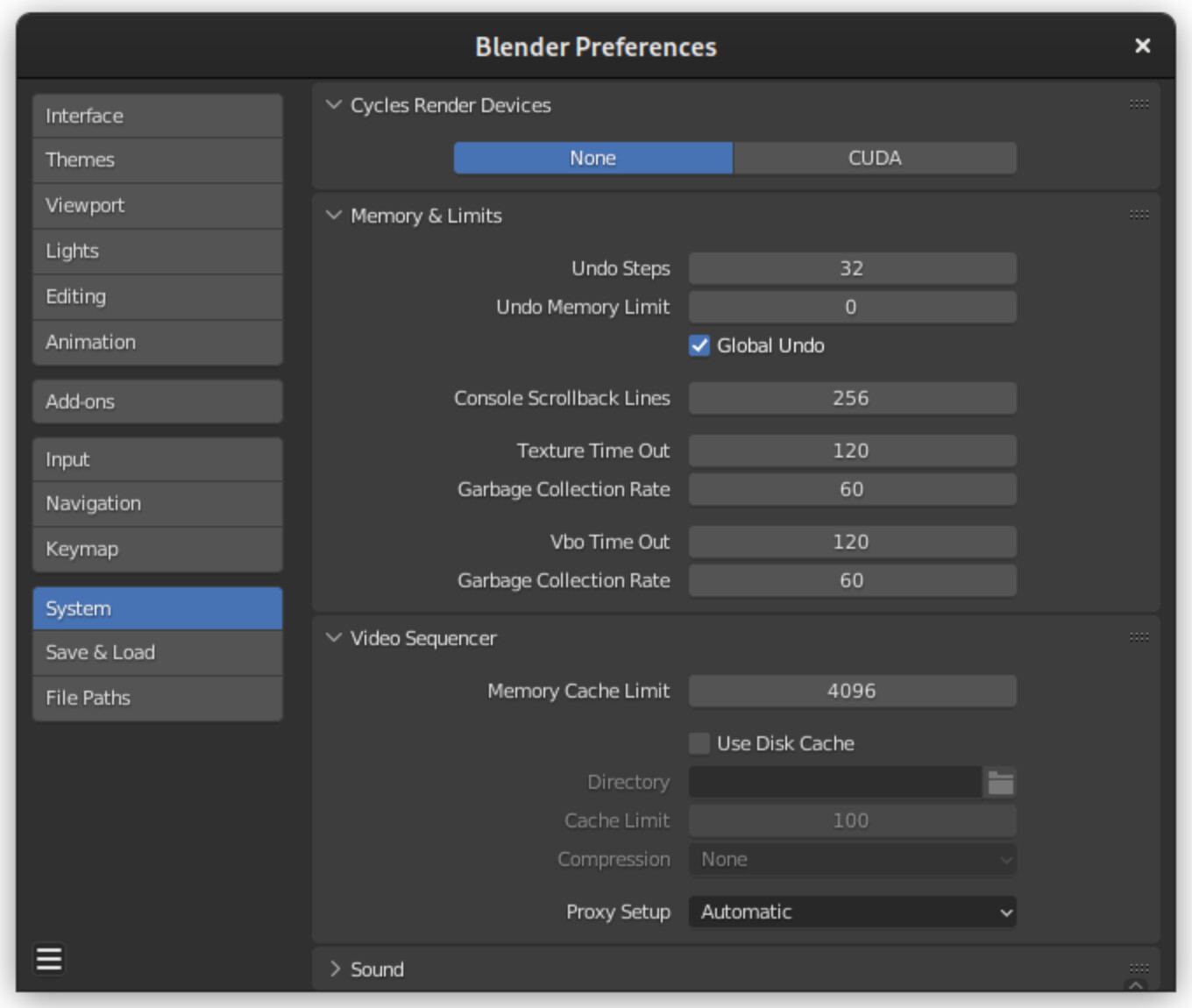
I apologize for oversharing. Despite my efforts to understand various components involved in GPU I remain quite confused about it. So below I share anything that might be meaningful for someone more knowledgeable than me.
I’m running Nix OS 21.11. Blender is installed with home-manager set to unstable channel. I’ve cloned and added the nixos-rocm overlay to .config/nixpkgs/overlays.nix.
nix-info -m
- system:
"x86_64-linux" - host os:
Linux 5.10.115, NixOS, 21.11 (Porcupine), 21.11.337526.8b3398bc758 - multi-user?:
yes - sandbox:
yes - version:
nix-env (Nix) 2.4pre20210317_8a5203d - channels(root):
"nixos-21.11.337526.8b3398bc758" - channels(tad):
"home-manager, nixpkgs" - nixpkgs:
/home/tad/.nix-defexpr/channels/nixpkgs
hipconfig
HIP version : 5.0.13601-
== hipconfig
HIP_PATH : /nix/store/xsq40ylwip8y1c2ig4m5kzpv8jgg9als-hip
ROCM_PATH : /opt/rocm
HIP_COMPILER : clang
HIP_PLATFORM : amd
HIP_RUNTIME : rocclr
CPP_CONFIG : -D__HIP_PLATFORM_HCC__= -D__HIP_PLATFORM_AMD__= -I/nix/store/xsq40ylwip8y1c2ig4m5kzpv8jgg9als-hip/include -I/nix/store/irhg5qp641nmfk5rjd428x29ybr60rsa-clang-wrapper-5.0.2/bin/../lib/clang/14.0.0 -I/nix/store/2mxnsmr1bgzsfxpw4rjckj77kkfyd4kx-rocm-runtime-5.0.2/include
== hip-clang
HSA_PATH : /nix/store/2mxnsmr1bgzsfxpw4rjckj77kkfyd4kx-rocm-runtime-5.0.2
HIP_CLANG_PATH : /nix/store/irhg5qp641nmfk5rjd428x29ybr60rsa-clang-wrapper-5.0.2/bin
clang version 14.0.0
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /nix/store/pkzy3kr860qq106y7aainfg5f1d9rsnl-clang-5.0.2/bin
AOMP-12.0-3 (http://github.com/ROCm-Developer-Tools/aomp):
Source ID:12.0-3-bebd719ff2bb58a4220658c708f91d486729dbc1
LLVM version 14.0.0git
Optimized build.
Default target: x86_64-unknown-linux-gnu
Host CPU: znver1
Registered Targets:
amdgcn - AMD GCN GPUs
r600 - AMD GPUs HD2XXX-HD6XXX
x86 - 32-bit X86: Pentium-Pro and above
x86-64 - 64-bit X86: EM64T and AMD64
hip-clang-cxxflags : -std=c++11 -isystem "/nix/store/pkzy3kr860qq106y7aainfg5f1d9rsnl-clang-5.0.2/lib/clang/14.0.0/include/.." -isystem /nix/store/2mxnsmr1bgzsfxpw4rjckj77kkfyd4kx-rocm-runtime-5.0.2/include -isystem /nix/store/2mxnsmr1bgzsfxpw4rjckj77kkfyd4kx-rocm-runtime-5.0.2/include -isystem "/nix/store/xsq40ylwip8y1c2ig4m5kzpv8jgg9als-hip/include" -O3
hip-clang-ldflags : -L"/nix/store/xsq40ylwip8y1c2ig4m5kzpv8jgg9als-hip/lib" -O3 -lgcc_s -lgcc -lpthread -lm -lrt
=== Environment Variables
PATH=/nix/store/igz15r204qlc6q1h8yzvzgdsl29mglnb-rocminfo-5.1.1/bin:/run/wrappers/bin:/home/tad/.nix-profile/bin:/etc/profiles/per-user/tad/bin:/nix/var/nix/profiles/default/bin:/run/current-system/sw/bin
HSA_PATH=/nix/store/2mxnsmr1bgzsfxpw4rjckj77kkfyd4kx-rocm-runtime-5.0.2
HIP_PATH=/nix/store/xsq40ylwip8y1c2ig4m5kzpv8jgg9als-hip
HIP_CLANG_PATH=/nix/store/irhg5qp641nmfk5rjd428x29ybr60rsa-clang-wrapper-5.0.2/bin
LD_LIBRARY_PATH=/nix/store/bb4xj0vzvyaxlc2d3140mlrnvds3nbn7-sane-config/lib/sane:/nix/store/nq5cmr5l4ma32602lgidhbhmpp10x3k0-telepathy-glib-0.24.2/lib:/nix/store/li8ddkdhlrx4avhqx1hk1x8ygc223d29-telepathy-logger-0.8.2/lib
== Linux Kernel
Hostname : tad-lispy-nixos
Linux tad-lispy-nixos 5.10.115 #1-NixOS SMP Thu May 12 10:25:46 UTC 2022 x86_64 GNU/Linux
rocminfo
ROCk module is loaded
=====================
HSA System Attributes
=====================
Runtime Version: 1.1
System Timestamp Freq.: 1000.000000MHz
Sig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)
Machine Model: LARGE
System Endianness: LITTLE
==========
HSA Agents
==========
*******
Agent 1
*******
Name: AMD Ryzen 7 4800H with Radeon Graphics
Uuid: CPU-XX
Marketing Name: AMD Ryzen 7 4800H with Radeon Graphics
Vendor Name: CPU
Feature: None specified
Profile: FULL_PROFILE
Float Round Mode: NEAR
Max Queue Number: 0(0x0)
Queue Min Size: 0(0x0)
Queue Max Size: 0(0x0)
Queue Type: MULTI
Node: 0
Device Type: CPU
Cache Info:
L1: 32768(0x8000) KB
Chip ID: 0(0x0)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 2900
BDFID: 0
Internal Node ID: 0
Compute Unit: 16
SIMDs per CU: 0
Shader Engines: 0
Shader Arrs. per Eng.: 0
WatchPts on Addr. Ranges:1
Features: None
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: FINE GRAINED
Size: 32346856(0x1ed92e8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 2
Segment: GLOBAL; FLAGS: KERNARG, FINE GRAINED
Size: 32346856(0x1ed92e8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 3
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 32346856(0x1ed92e8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
ISA Info:
*******
Agent 2
*******
Name: gfx90c
Uuid: GPU-XX
Marketing Name:
Vendor Name: AMD
Feature: KERNEL_DISPATCH
Profile: BASE_PROFILE
Float Round Mode: NEAR
Max Queue Number: 128(0x80)
Queue Min Size: 64(0x40)
Queue Max Size: 131072(0x20000)
Queue Type: MULTI
Node: 1
Device Type: GPU
Cache Info:
L1: 16(0x10) KB
Chip ID: 5686(0x1636)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 1600
BDFID: 1024
Internal Node ID: 1
Compute Unit: 7
SIMDs per CU: 4
Shader Engines: 1
Shader Arrs. per Eng.: 1
WatchPts on Addr. Ranges:4
Features: KERNEL_DISPATCH
Fast F16 Operation: TRUE
Wavefront Size: 64(0x40)
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Max Waves Per CU: 40(0x28)
Max Work-item Per CU: 2560(0xa00)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
Max fbarriers/Workgrp: 32
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 524288(0x80000) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: FALSE
Pool 2
Segment: GROUP
Size: 64(0x40) KB
Allocatable: FALSE
Alloc Granule: 0KB
Alloc Alignment: 0KB
Accessible by all: FALSE
ISA Info:
ISA 1
Name: amdgcn-amd-amdhsa--gfx90c:xnack-
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
FBarrier Max Size: 32
*** Done ***
clinfo
Number of platforms 1
Platform Name AMD Accelerated Parallel Processing
Platform Vendor Advanced Micro Devices, Inc.
Platform Version OpenCL 2.0 AMD-APP (3305.0)
Platform Profile FULL_PROFILE
Platform Extensions cl_khr_icd cl_amd_event_callback
Platform Extensions function suffix AMD
Platform Name AMD Accelerated Parallel Processing
Number of devices 1
Device Name gfx902:xnack-
Device Vendor Advanced Micro Devices, Inc.
Device Vendor ID 0x1002
Device Version OpenCL 2.0
Driver Version 3305.0 (HSA1.1,LC)
Device OpenCL C Version OpenCL C 2.0
Device Type GPU
Device Board Name (AMD) Device 1636
Device PCI-e ID (AMD) 0x1636
Device Topology (AMD) PCI-E, 0000:04:00.0
Device Profile FULL_PROFILE
Device Available Yes
Compiler Available Yes
Linker Available Yes
Max compute units 7
SIMD per compute unit (AMD) 4
SIMD width (AMD) 16
SIMD instruction width (AMD) 1
Max clock frequency 1600MHz
Graphics IP (AMD) 9.0
Device Partition (core)
Max number of sub-devices 7
Supported partition types None
Supported affinity domains (n/a)
Max work item dimensions 3
Max work item sizes 1024x1024x1024
Max work group size 256
Preferred work group size (AMD) 256
Max work group size (AMD) 1024
Preferred work group size multiple (kernel) 64
Wavefront width (AMD) 64
Preferred / native vector sizes
char 4 / 4
short 2 / 2
int 1 / 1
long 1 / 1
half 1 / 1 (cl_khr_fp16)
float 1 / 1
double 1 / 1 (cl_khr_fp64)
Half-precision Floating-point support (cl_khr_fp16)
Denormals No
Infinity and NANs No
Round to nearest No
Round to zero No
Round to infinity No
IEEE754-2008 fused multiply-add No
Support is emulated in software No
Single-precision Floating-point support (core)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations Yes
Double-precision Floating-point support (cl_khr_fp64)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Address bits 64, Little-Endian
Global memory size 536870912 (512MiB)
Global free memory (AMD) 524288 (512MiB) 524288 (512MiB)
Global memory channels (AMD) 4
Global memory banks per channel (AMD) 4
Global memory bank width (AMD) 256 bytes
Error Correction support No
Max memory allocation 456340272 (435.2MiB)
Unified memory for Host and Device No
Shared Virtual Memory (SVM) capabilities (core)
Coarse-grained buffer sharing Yes
Fine-grained buffer sharing Yes
Fine-grained system sharing No
Atomics No
Minimum alignment for any data type 128 bytes
Alignment of base address 1024 bits (128 bytes)
Preferred alignment for atomics
SVM 0 bytes
Global 0 bytes
Local 0 bytes
Max size for global variable 456340272 (435.2MiB)
Preferred total size of global vars 536870912 (512MiB)
Global Memory cache type Read/Write
Global Memory cache size 16384 (16KiB)
Global Memory cache line size 64 bytes
Image support Yes
Max number of samplers per kernel 5686
Max size for 1D images from buffer 134217728 pixels
Max 1D or 2D image array size 8192 images
Base address alignment for 2D image buffers 256 bytes
Pitch alignment for 2D image buffers 256 pixels
Max 2D image size 16384x16384 pixels
Max 3D image size 16384x16384x8192 pixels
Max number of read image args 128
Max number of write image args 8
Max number of read/write image args 64
Max number of pipe args 16
Max active pipe reservations 16
Max pipe packet size 456340272 (435.2MiB)
Local memory type Local
Local memory size 65536 (64KiB)
Local memory size per CU (AMD) 65536 (64KiB)
Local memory banks (AMD) 32
Max number of constant args 8
Max constant buffer size 456340272 (435.2MiB)
Preferred constant buffer size (AMD) 16384 (16KiB)
Max size of kernel argument 1024
Queue properties (on host)
Out-of-order execution No
Profiling Yes
Queue properties (on device)
Out-of-order execution Yes
Profiling Yes
Preferred size 262144 (256KiB)
Max size 8388608 (8MiB)
Max queues on device 1
Max events on device 1024
Prefer user sync for interop Yes
Number of P2P devices (AMD) 0
Profiling timer resolution 1ns
Profiling timer offset since Epoch (AMD) 0ns (Thu Jan 1 01:00:00 1970)
Execution capabilities
Run OpenCL kernels Yes
Run native kernels No
Thread trace supported (AMD) No
Number of async queues (AMD) 8
Max real-time compute queues (AMD) 8
Max real-time compute units (AMD) 7
printf() buffer size 4194304 (4MiB)
Built-in kernels (n/a)
Device Extensions cl_khr_fp64 cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_fp16 cl_amd_device_attribute_query cl_amd_media_ops cl_amd_media_ops2 cl_khr_image2d_from_buffer cl_khr_subgroups cl_khr_depth_images cl_amd_copy_buffer_p2p cl_amd_assembly_program
NULL platform behavior
clGetPlatformInfo(NULL, CL_PLATFORM_NAME, ...) AMD Accelerated Parallel Processing
clGetDeviceIDs(NULL, CL_DEVICE_TYPE_ALL, ...) Success [AMD]
clCreateContext(NULL, ...) [default] Success [AMD]
clCreateContextFromType(NULL, CL_DEVICE_TYPE_DEFAULT) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx902:xnack-
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CPU) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_GPU) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx902:xnack-
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ACCELERATOR) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CUSTOM) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ALL) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx902:xnack-
ICD loader properties
ICD loader Name OpenCL ICD Loader
ICD loader Vendor OCL Icd free software
ICD loader Version 2.3.1
ICD loader Profile OpenCL 3.0