Around June last year, myself and @zimbatm started looking into what it would take to garbage collect https://cache.nixos.org.
It started out as a project called Narwal, and took the form of a write-through proxy for Hydra, which would track everything going into the S3 bucket and import historical state via the S3 Inventory Service. From there, GC strategies could be researched and implemented, and we could finally GC https://cache.nixos.org and reduce the running costs.
When we started, the free credits from AWS were just about covering the S3 bucket, but since then, growth has meant the foundation is having to pay each month in addition to the free credits, at an ever-increasing rate.
As usually happens, life and work got in the way, and we never got around to finishing it.
Fast-forward to last month, when I found myself with some time to move things forward again. That’s when I discovered our original approach was no longer viable due to upcoming changes to the queue runner in Hydra. After speaking with @Conni2461 during the bi-weekly Queue Runner meeting, I was also informed, to my surprise, that Hydra already retained partial knowledge of “every store path” in the bucket.
Checking what Hydra knows
There is a table in Hydra called buildstepoutputs. As the name suggests, it contains an entry for every store path created by Hydra. From there, it’s possible to infer the S3 key for the corresponding .narinfo and other artefacts within the S3 bucket, and from the .narinfo you can then infer the Nar URL.
@hexa was under the impression this state had never been cleaned up, so it should, in theory, match up with the S3 bucket. So I set out to validate this, and here’s what I found.
Starting with the S3 inventory, I extracted the hash for every .narinfo key in the bucket. I then attempted to correlate that with the hash component of the path column within buildstepoutputs. What I found was ~99.5% of all narinfos within the S3 bucket have a corresponding entry in buildstepoutputs.
What about the 0.5% that didn’t?
My initial thought was that the missing ~0.5% was probably related to early in Hydra’s history. But when I started creating some graphs, I discovered what appears to be an ongoing issue that has been happening since the very beginning.
Here are some plots showing the daily rate that narinfos were added to the S3 bucket and comparing them with buildstepoutputs. As you can see, on a daily basis, there are narinfos making it into the S3 bucket which do not have an entry in buildstepoutputs.
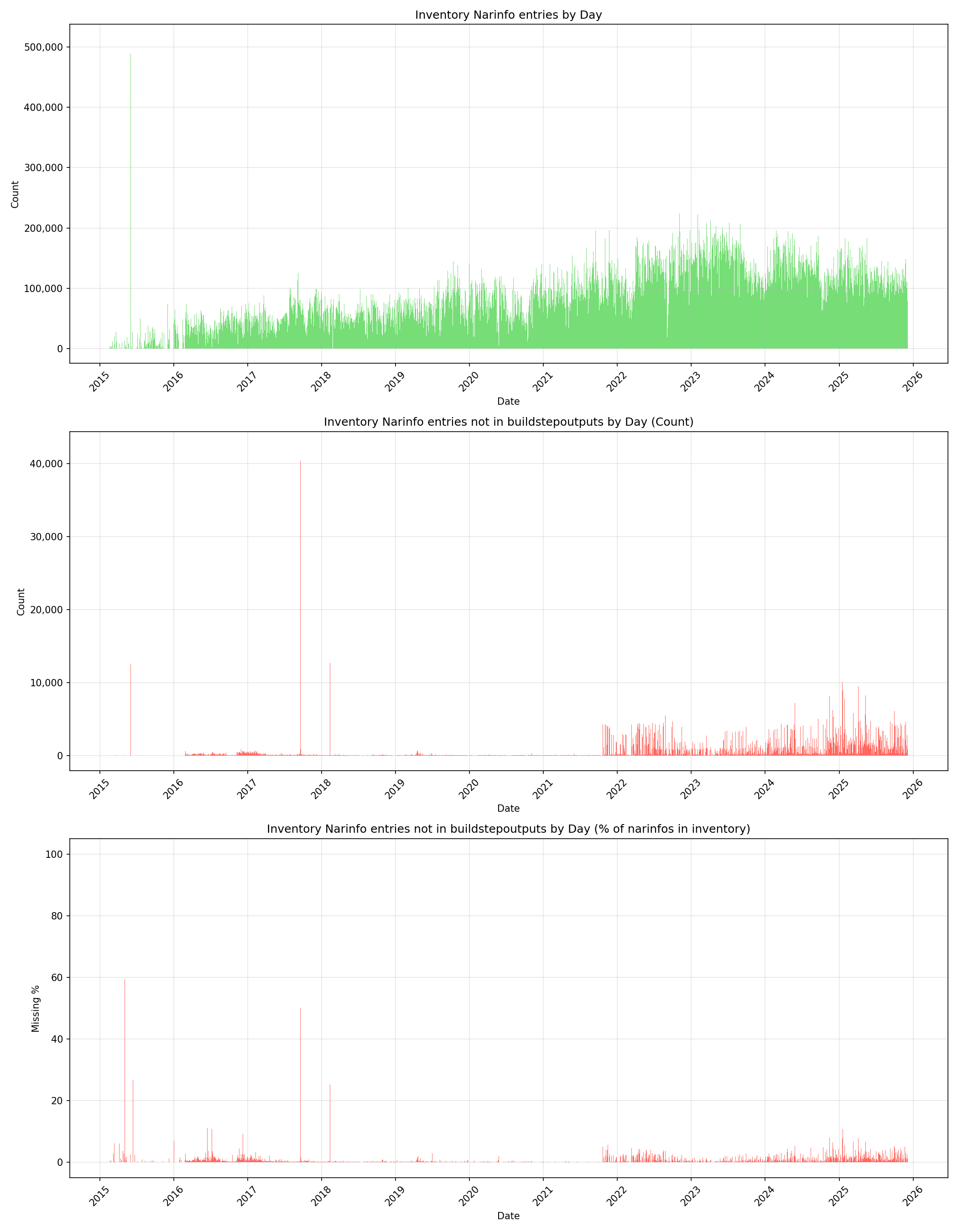
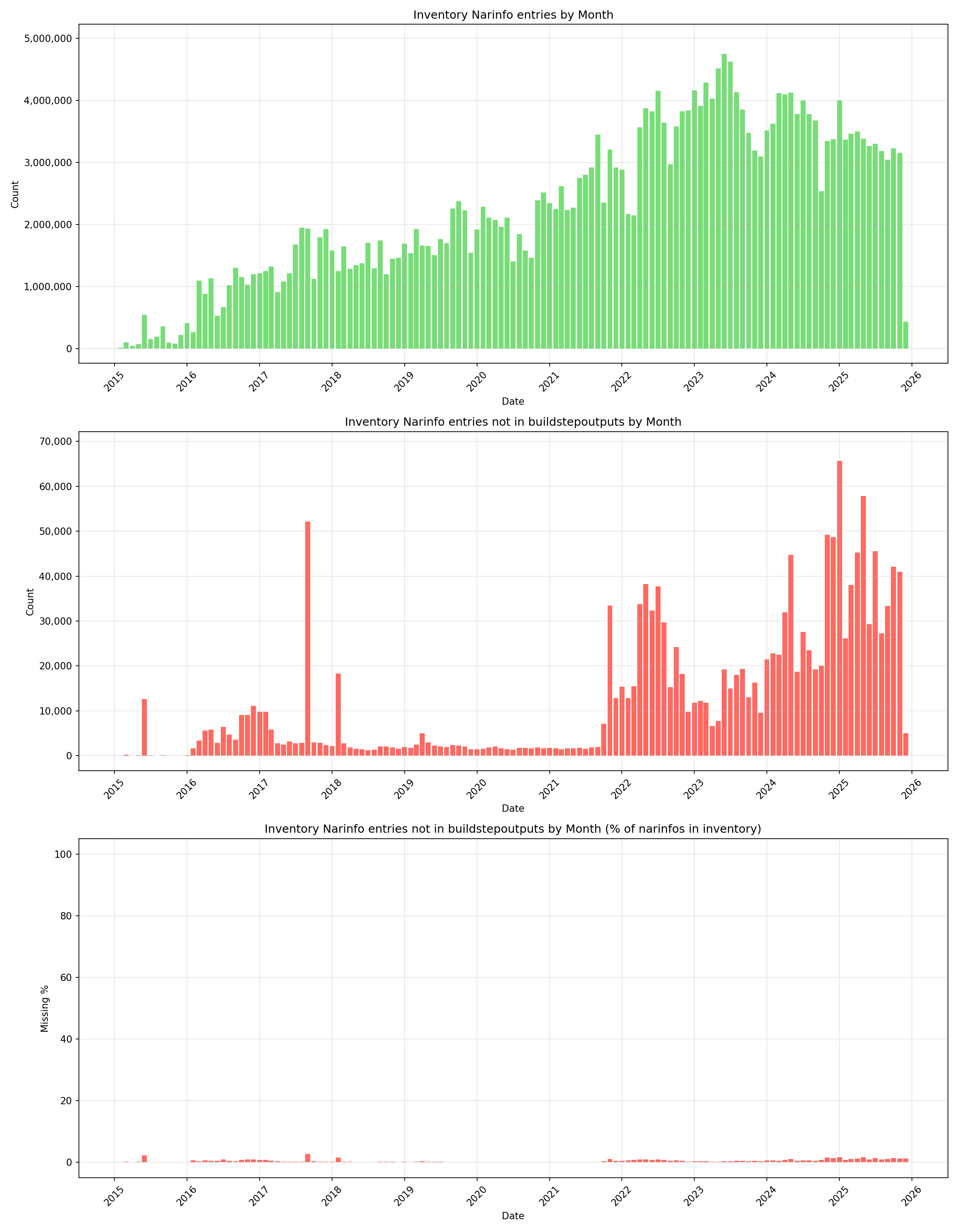
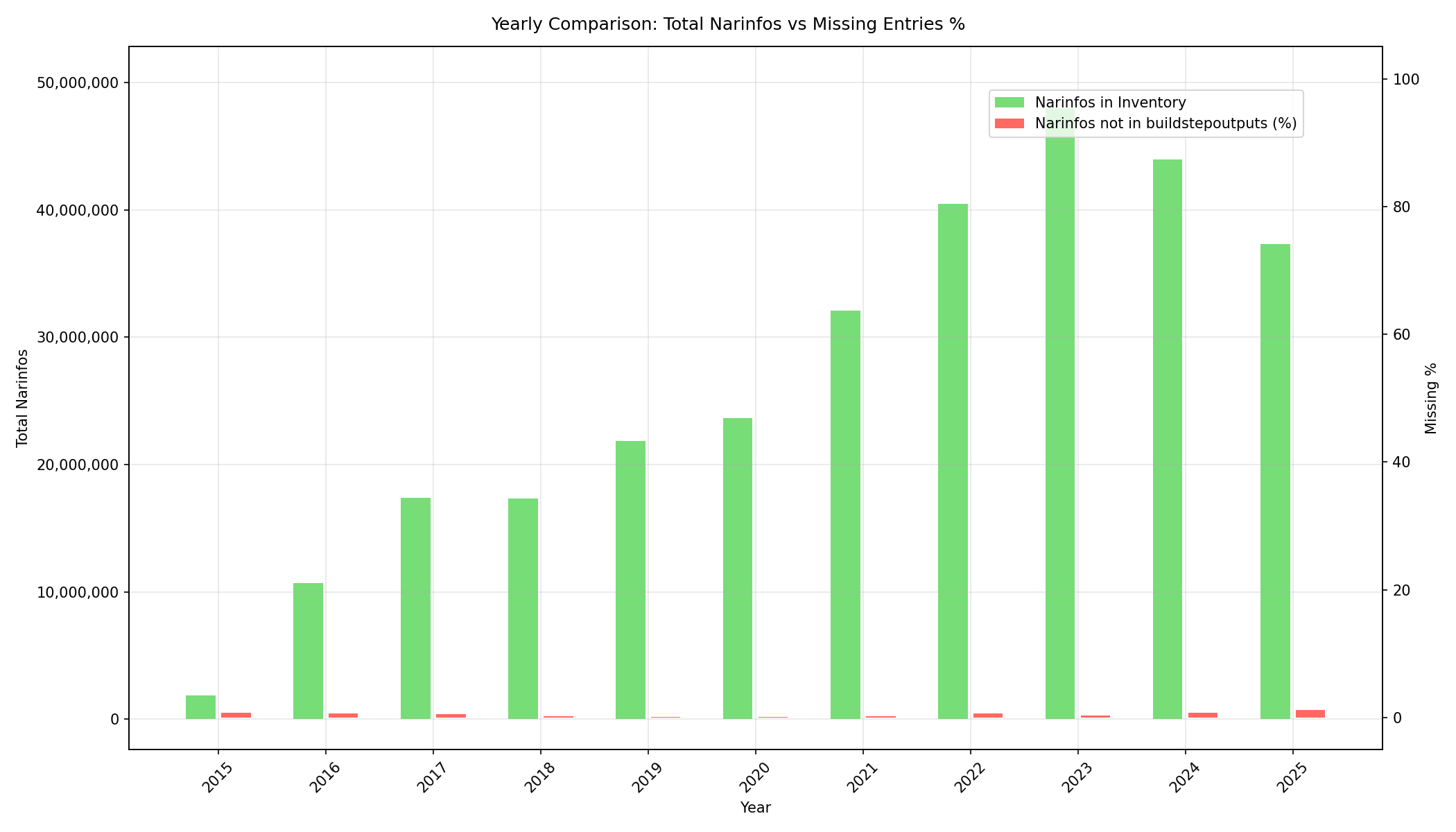
We have nearly all the data, though, right?
Putting the issue of the “orphans” to one side for a second, it would appear @Conni2461‘s assertion was correct: Hydra does at least have the beginnings of the state we would need to garbage collect the S3 bucket.
What it lacks, though, is knowledge of how store paths relate to each other (the References field in narinfo) and the Nar URL (also in narinfo), which is content-addressed and cannot be derived. But this information can be added.
I did a quick experiment to see what impact it would have if we imported references from the existing narinfos and have queue runner start tracking them going forward: it adds ~210 GB of additional storage overall in the short term (until we garbage collect at least once).
So what next?
After speaking with @Conni2461, @Mic92, @Ericson2314 the current thinking is that it makes sense to add the missing data needed to reason about garbage collection to Hydra.
This would take the form of a historical import from the bucket, based on the work already done in Narwal, and a change to the new Rust rewrite of the Queue Runner to keep things up to date.
Once implemented, we can start work on a new GC component (likely Rust, in keeping with the general direction) that will implement the GC workflow. There were some experiments within Narwal around creating introspectable GC plans before applying them, which could be resurrected and built upon.
At the same time, we need to find out where these “orphans” are coming from. I think @Conni2461 has some ideas where to look.
Low hanging fruit
Being mindful of the ever-increasing cost of the S3 bucket, @mic92 has proposed a quick win: identifying and removing any NixOS images uploaded to the cache. Anything important already has copies elsewhere, and there’s an argument that they shouldn’t have been uploaded in the first place.
This should reduce the cache by nearly 100TB or 13.6%, which should bring us under the free credit limit and buy us more time to implement “proper” GC.
❯ duckdb
-- Loading resources from /nix/store/wvcn7xhhs23r6m148hhbzi8b93gh5z9g-init.sql
DuckDB v1.4.3 (Andium) d1dc88f950
Enter ".help" for usage hints.
D select formatReadableSize(sum(file_size)::BigInt) as file_size, count(*) from 'datasets/narinfos-2026-01-06T01-13Z.parquet';
┌───────────┬──────────────┐
│ file_size │ count_star() │
│ varchar │ int64 │
├───────────┼──────────────┤
│ 720.2 TiB │ 297634067 │
└───────────┴──────────────┘
D select formatReadableSize(sum(file_size)::BigInt) as file_size, count(*) from 'datasets/narinfos-nixos-images-2026-01-06T01-13Z.parquet';
┌───────────┬──────────────┐
│ file_size │ count_star() │
│ varchar │ int64 │
├───────────┼──────────────┤
│ 98.3 TiB │ 150581 │
└───────────┴──────────────┘
Since I already have every narinfo up until 6th January 2026, and Narwal allows me to incrementally fetch new narinfos as the inventory is updated, it’s possible to filter that dataset by pname and try to identify NixOS images.
To that end, I have already made a start here. You can find that dataset, including a complete inventory of the cache, a copy of all the narinfos in the cache, and other supporting datasets here. Please review it and verify the methodology ![]() .
.
In addition, I have implemented a gc simple command in Narwal to apply this dataset and remove the associated .narinfo and .nar files from the cache, cleaning up the buildstepoutput table in the process. Again, I would like more eyes on this, and gladly welcome more people to share the blame with in case we end up destroying https://cache.nixos.org ![]() .
.
Since these things have a tendency to drag on without a deadline, I’d also like to propose the end of this month as a target to reap the NixOS images unless there are any good reasons not to.