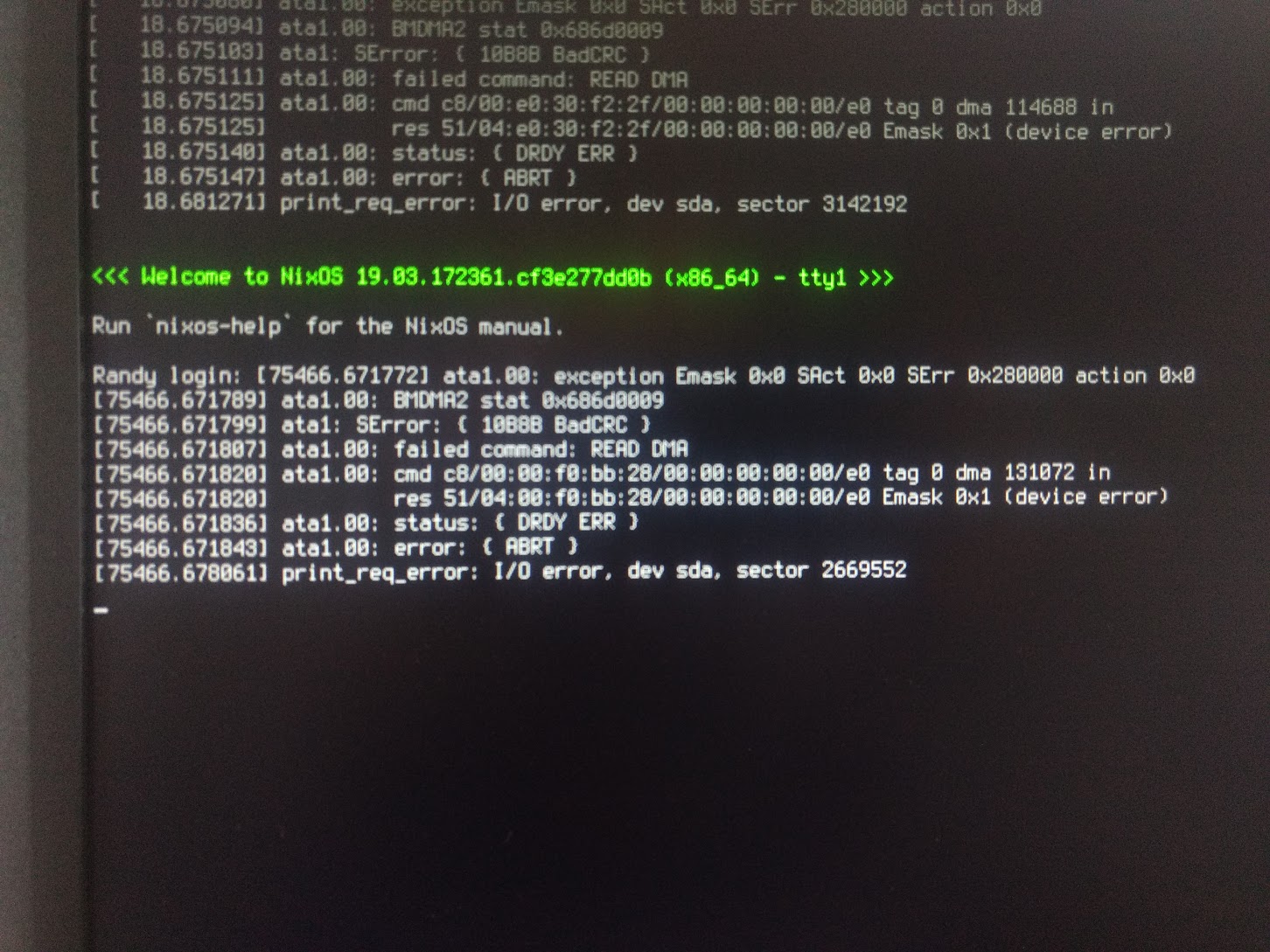
These errors show up every time the computer boots.
I tried latest kernel and also older versions like 4.14. I also have kernel params “libata.force=noncq”.
How to fix that?
These errors show up every time the computer boots.
I tried latest kernel and also older versions like 4.14. I also have kernel params “libata.force=noncq”.
How to fix that?
That isn’t a good sign, I only had those issues when my drive or cables were actually defective. When I suspected software issues in the past it turned out that changing hardware fixed the issue after all.
I would try running smartctl -a /dev/$device (replace $drive with the name of the affected device) from the smartmontools package and look for issues in the bottom section of that output. You can post it here and I can take a look.
Also you should do a backup of your data asap if you don’t have one already, if the issue gets worse.
As it is a laptop I either expect it to be a drive issue, a broken connector of the drive or the slot where the drive sits, or some issue on the notebook mainbook. If you have access to another notebook drive and your notebook drive can be easily changed I would try copying your system to that drive and boot from there.
If there are issues during copying your data you might want to have a look at the ddrescue package. One tip: use a mapfile and don’t place it on the drive you are recovering. ![]()
Here’s the output of smartctl
After the errors I’ve replaced with a brand new disk. I suspected the cable, too so I tried another one but the errors remain.
Yeah, SMART tells you the same story, that errors happend during communication. The SMART Attributes seem to be OK, and the selftests ran fine. So I wouldn’t suspect the disc, esp. as you tried another one. ![]()
If you can see the mainboard, does it look corroded around the hard disk connector or do you see bend pins? That would be the only thing I can think of that would be relatively easy to diagnose.
To exclude a software issue, I would try installing another distro, but I can’t imagine that would make a difference, as NixOS uses the normal Linux kernel with a sensible configuration.
I hope you can find the issue!
smartctl 7.0 2018-12-30 r4883 [x86_64-linux-4.19.36] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red
Device Model: WDC WD10EFRX-68FYTN0
Serial Number: WD-WCC4J5VJVZF0
LU WWN Device Id: 5 0014ee 264fea8a0
Firmware Version: 82.00A82
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2 (minor revision not indicated)
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 1.5 Gb/s)
Local Time is: Tue Apr 30 15:40:41 2019 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (13020) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 148) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x303d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 141 139 021 Pre-fail Always - 3908
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 9
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 77
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 9
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 6
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 182
194 Temperature_Celsius 0x0022 110 110 000 Old_age Always - 33
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 193 000 Old_age Always - 210
200 Multi_Zone_Error_Rate 0x0008 100 253 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
Just did some testing… It turns out that its the PCI SATA card I’m using.
As Kerwood pointed out it can also be the controller, I had the same error on my old laptop, luckily on the SATA port that connected the optical drive. Couldn’t fix it as it was embedded in the motherboard
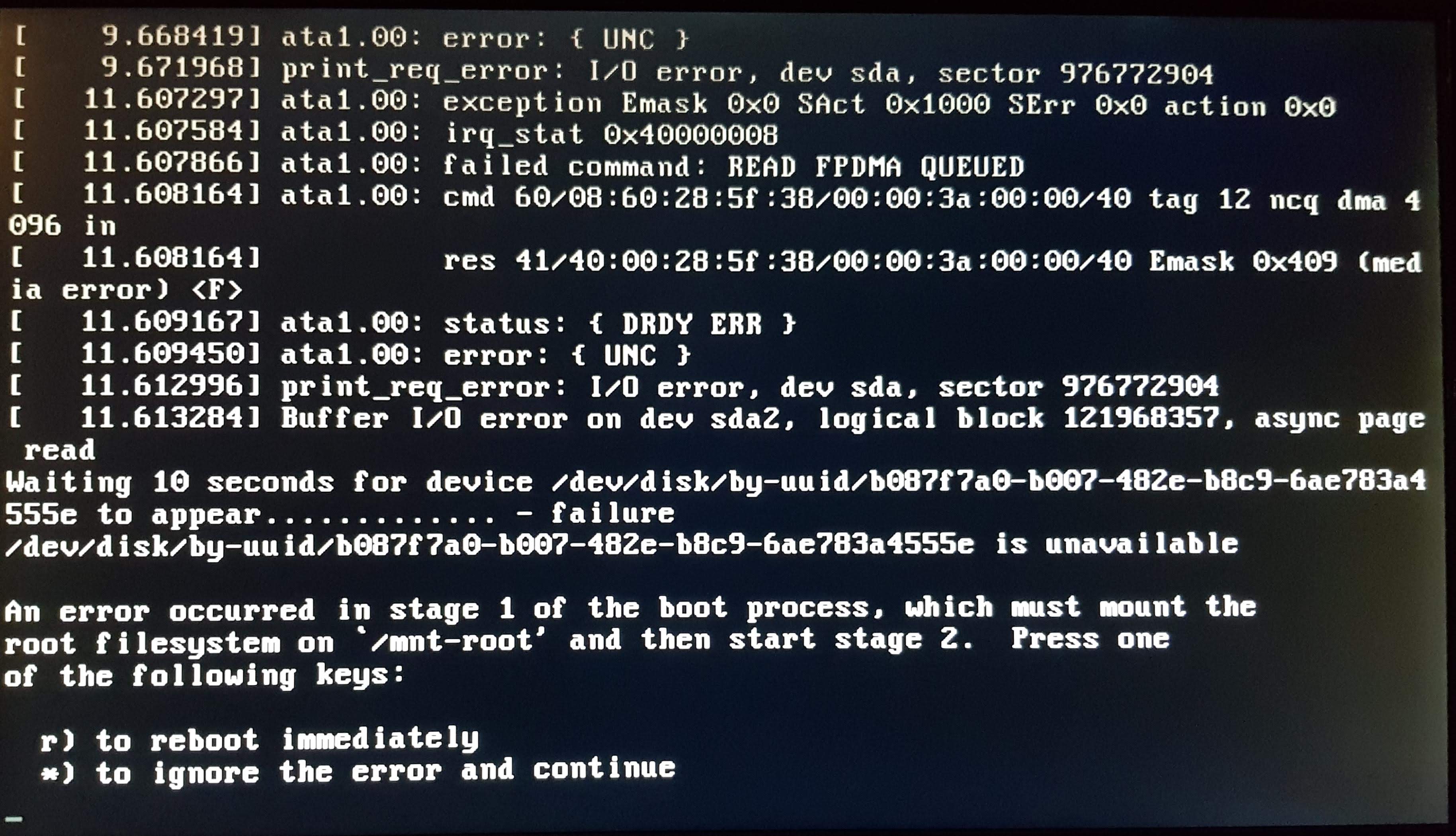
I left my local file server running for about a month, and did many things on it, including nixos-rebuild switch.
However, when I rebooted, I see those same errors and I could no longer boot it! The SATA connectors are soldered on the motherboard. I have tried different combinations in the BIOS/UEFI settings but it still won’t work.
Before any of these occurred, I ran smartctl on the drive a month earlier, and no errors were reported.
I don’t know where to go next from here.
What does “I could no longer boot it” mean?
Here’s a photo of the screen where the error appears:
Did you try booting with another live distro and see what happens if you try to access the disk?