Last year we started work on rewriting the Hydra Queue Runner, the core Hydra service that is responsible for splitting toplevel jobs into steps and scheduling them on separate machines.
We (@conni2461 and myself) have done this work together with the NixOS Infra team @hexa, @mic92 and got awesome support from @ericson2314.
A significant downside with the C++ implementation lies in the communication between the Queue Runner and the builders.
This system, built on SSH, directly interfaced with the Nix daemons of the builders, requiring an expensive SSH handshake for each build and being hard to debug when issues like the lack of SSH known host keys occured.
Additionally, the scheduling mechanism handled all architectures in a single queue, starving one architecture like x86_64-linux from new builds when other architectures like aarch64-darwin were overly busy.
To solve these limitations, we redesigned and reimplemented the Queue Runner in Rust using gRPC for communication with the builders.
This also allowed us to switch the direction of communication, where the builder connects to the Queue Runner rather than the Queue Runner requiring prior knowledge about the builder.
It also allows us to introduce generic messages unrelated to the Nix protocol between Queue Runner and builder, which enables monitoring of the system utilization of all builders and allows us to make more sophisticated scheduling decisions and give more information to the user:
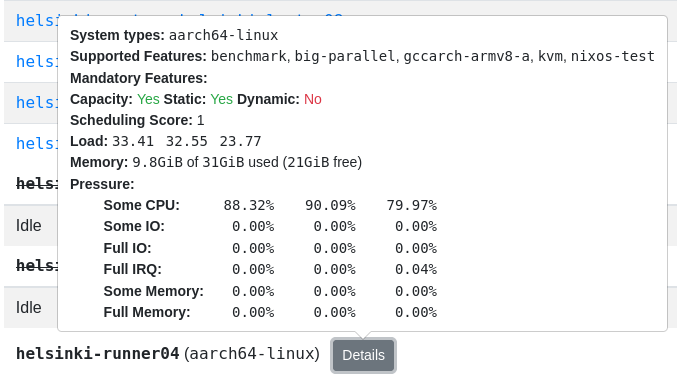
We also re-engineered the queueing mechanism to split the queue between architectures and implemented different scheduling strategies to ensure we don’t give already overloaded builders even more work.
Using the new Queue Runner does not require any database changes, as it adheres to the same interface, writes the same information to the database and also communicates with the other Hydra components via PostgreSQL NOTIFY.
The majority of the development took place in a separate repository and is planned be merged into the Hydra repository.
We also presented the solution at the last NixCon.
The new implementation is in use by Helsinki Systems internally, and was also temporarily used by the Nix-Community Hydra.
Timeline
We are close to going to production and replacing the current C++ implementation of the Hydra Queue Runner. The current timeline is:
- Deploy new builder service to all builder hosts in NixOS Infra
- Do some final testing of the Queue Runner RS on the staging Hydra this weekend
- Get the Hydra test suite to run with the new Queue Runner
- After that we plan the switch of the C++ Queue Runner, disabling the old Queue Runner and deploying the new one permanently. If there are any unforeseen consequences, we can switch back to the C++ Queue Runner
- The goal is to have this done by the next meeting
- After that we will look into a 64-bit timestamp migration, because all timestamps are currently still 32-bit. We have the old database server for testing the migration and determining the expected downtime
- Roughly 2-3 weeks later we plan to deploy presigned URLs (depending on how everything eles goes). This is a new features which allows builders to directly upload build outputs to S3 rather than pushing them to the Queue Runner first which then uploads to S3 - eliminating yet another bottleneck of the old design
- This is already implemented and is currently being tested
Meeting
In the past few months we met every two weeks on Thursday evening 6PM CEST.
We moved the date to Tuesday 6PM CEST and agreed to make this meeting public, allowing anyone to join.
The next meeting will be on 2026-02-10T17:00:00Z.
Meeting notes: https://md.darmstadt.ccc.de/queue-runner-rs
Meeting link: LaSuite Meet
Whats next for Hydra
There are no concrete timelines for the upcoming features. There is however a rough roadmap of things we would like to do in the (near) future.
- 2026
- Hydra evaluator rewrite to get rid of C++ code (leaving us with only Rust and Perl <3)
- Plan the v2 API and implementing parts of it alongside the v1 API
- Figure out if we want to replace PostgreSQL
NOTIFYwith something else and with what - OfBorg and improved GitHub Pull Requests integration
- Live log tailing - there is a POC already
- More detailed tests
- 2027
- Replace web interface with a new CSR implementation that uses the v2 API
Last but not least with that post we also want to announce that we are in discussion with the SC to form a new Hydra team that is responsible for our Continous Integration System. Initial members of this team will be @das_j @mic92 @ericson2314 @conni2461