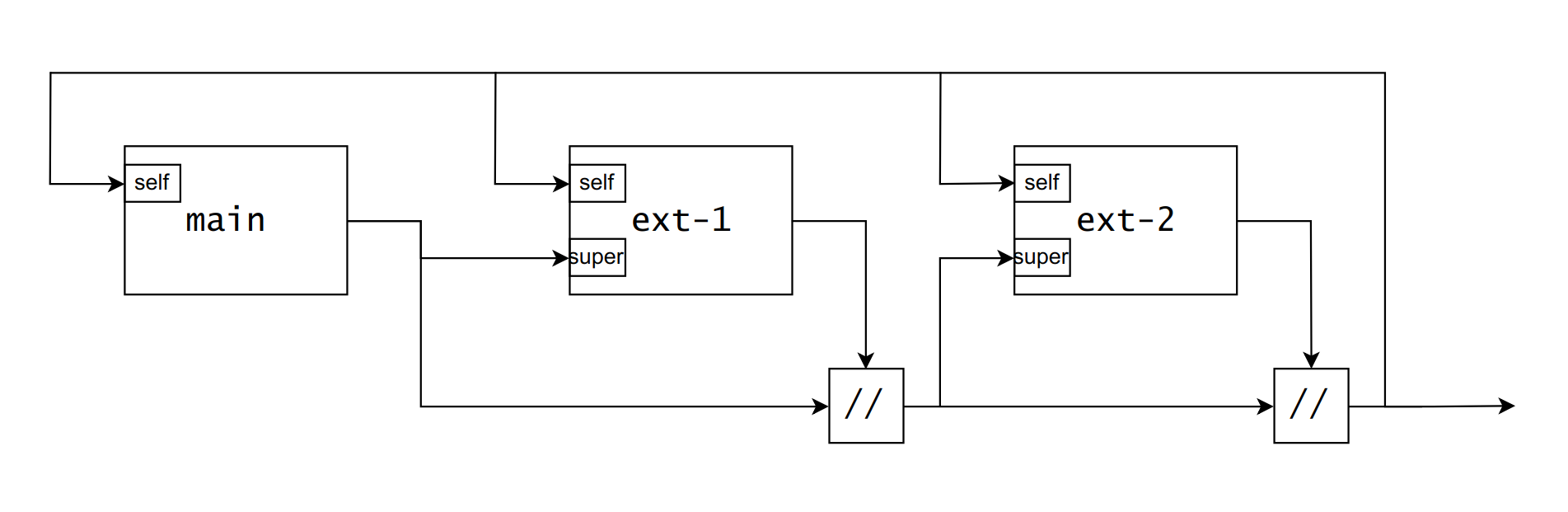
Overlays are given both self and super. If I’m overriding a package, it’s pretty obvious that I need to use super.packageName to reference the package to override. But for other references it’s less clear as to when I should be using self vs super.
So far I’ve tended to default to using self, with the assumption that if the thing I’m referencing is overridden in another overlay, I probably want the overridden version, but I’m also seeing plenty of examples of code that use super for various references and I’m not sure if there’s a reason.
For example, in @LnL7’s overlay it defines nix-rebuild as
nix-rebuild = super.writeScriptBin "nix-rebuild" ''
#!${super.stdenv.shell}
if ! command -v nix-env &>/dev/null; then
echo "warning: nix-env was not found in PATH, add nix to userPackages" >&2
PATH=${self.nix}/bin:$PATH
fi
exec nix-env -f '<nixpkgs>' -r -iA userPackages "$@"
'';
This uses super.writeScriptBin and super.stdenv.shell when these would presumably work just as well as self.writeScriptBin and self.stdenv.shell.
In this case the super.boost reference is obviously correct, but why does it use super.callPackage instead of self.callPackage? Not that I expect callPackage to be overridden, but is there any particular reason to be pulling this from super? The documentation does say that super should be used “to refer to packages you wish to override, or to access functions defined in Nixpkgs”, but it doesn’t provide any justification for using it to access functions.
Thanks. I watched a good portion of that and it did a good job talking through a number of overlay examples, but the presenter never actually explained why functions should be taken from super. The explanation was basically “dependencies should be taken from self, everything else from super”. I get that the self argument is provided specifically for dependencies, but it’s still not obvious to me why using it for functions is considered wrong.
About the only reason I can really think of is the functions themselves aren’t supposed to be replaced with new versions, but if an overlay does do this, then any reference to it using self would be broken whereas a reference with super would work. Unless the function was replaced with a wrapper that is intended to take the place of the original (e.g. it just dumps a trace message and then calls the original version with the same arguments), in which case that would only work if references to it used self.
In fact, for packages in nixpkgs itself, aren’t the library functions they reference ultimately references via self? These packages don’t have access to super, so AFAIK all the arguments they’re given come from the fixed point, meaning references to lib or stdenv.lib are all effectively accesses via self. This would suggest that overlays should in fact declare that “super is only for overriding packages, self for everything else”.
I agree with your analysis. The talk posted above does elaborate slightly in the Q&A, but he basically just briefly mentions grafting in a way I didn’t understand. I think he was saying that grafting will allow us to un-fix the overlays and add a new one, with a slight difference being that things like callPackage from the old overlays will still use the old fixed self, not the one post-graft. But I’m not clear on A) Why this is a problem, or B) Why this design makes sense in the first place.
Oh wow looking ahead I stopped just before a detailed examination of what the mozilla overlay is doing. Apparently I need to find the time to watch this whole video.
Anyway, the Q&A gave basically two answers. The first is that using self.someLibFunction is going through the fixed point, so it’s a little slower, and also in the case of e.g. self.callPackage the function itself will go back through the fixed point again for dependencies. So that’s just extra work. But the second was referring to something called “grafting” which wasn’t really explained besides something about “peeling off the fixed point” so it can add another version of nixpkgs and do something with deltas. It’s really unclear though, and it’s also not clear why going through the fixed point twice for this is a problem given that the fixed point is, by definition, fixed (i.e. evaluating it N+1 times is no different than evaluating it N times).
I’ve found an RFC for Simple Override Strategy which is what this talk was referring to, but it doesn’t seem to describe grafting either, its only mention of grafting is that one of its benefits is “Normalize inputs of packages, to be used for future grafting techniques”.
nbp has a comment on that RFC that mentions grafting, and references NixOS/nixpkgs#10851 as the motivation, though that issue doesn’t actually mention the term “graft” anywhere. Reading through the issue description, it seems that the goal is actually to get rid of the fixed point and allow a “patched” version of nixpkgs as the final result, where all dependencies come from the unpatched version, and only patched packages have changed hashes. I’m still not sure why library functions have to come from super in this world, as presumably the library functions in the patched version of nixpkgs are identical to the ones in the unpatched.
Ultimately, the RFC and motivating issue have both been closed as stalled out, so it’s not clear what’s going to happen in the future with this. Given that, my expectation is that, as it stands today, using self instead of super to acquire library functions won’t hurt anything beyond potentially being marginally slower to evaluate (though surely, once a function has been accessed from self once, it will no longer be lazy and thus subsequent accesses should be faster), and should be more consistent with how library functions are used in callPackage-based packages. In the future, there may be some reason to prefer using super to acquire library functions, though in that future I guess we’re not using callPackage anymore.
super.callPackage goes through the fixed point as well. Getting the function itself doesn’t, but actually using it will provide arguments to the called package from the fixed point. This is what makes the grafting stuff sound strange to me; it sounds like it changes this behavior in a complicated way.
Using self for functions works fine but it’s pointless to go through the extra steps if they won’t influence the result. My takeaway was that using self for things that are never overridden, particularly callPackage, will have a memory and performance impact compared to super.
and this will print out a whole bunch of traces for every callPackage that’s invoked in order to produce the derivation for nixpkgs.exa (which works because all accesses from within the base nixpkgs set are effectively accesses on self).
As for memory and performance impact, once self.callPackage has been forced, there shouldn’t be any performance impact to accessing it. For example, if I instrument it a bit differently:
this prints out 6 lines saying trace: forcing callPackage, and then that trace will never happen again, even when accessing other packages. I’m assuming the 6 lines have something to do with forcing the expression through various stages of nixpkgs, but I’m not really certain of the details here. In any case, the point is that once it’s been forced, subsequent accesses don’t re-evaluate it. And since self is the same for all stages, this means that once anyone forces it on self, it’s forced for everyone.
Another argument for considering self.callPackage acceptable is that a package can take callPackage as an argument, and calling that package will give it self.callPackage. i.e.
callPackage ./foo.nix {}
# foo.nix
{ callPackage, ... }: ...
If we make things that depend on self.callPackage not being used, code like this will break, and there won’t be a sane way to fix that.
Apologies for the necrobump, but as a recent nix convert I’ve had this question as well.
@lilyball I know you’re still active in the community (and always very helpful – thank you). 4 years later, do you have anything more conclusive to say about this matter than what’s above?
As you’ve gained experience, what is your current practice? Do you default to self or super when it seems that either will do, and why? TIA!
My conclusion from writing overlays for some years is that the only good reason for using super is to access attributes you want to override, to avoid infinite recursion. This effectively means that the resulting attribute set can be represented with a single fixed-point function self: { ... } and everything can be further overridden without any hidden values being unchangeable. This also makes a lot of sense if you think of overlays as just a way to extend such a fixed-point function (which they are, see also lib.makeExtensible).
Some examples (untested):
self: super: {
# We override hello here, so `super.hello`
hello = super.hello.override {
# We don't override fetchurl here, so `self.fetchurl`
fetchurl = args: builtins.trace "fetchurl" self.fetchurl args;
};
fetchurl = args:
# We don't override hello here, so `self.hello`
builtins.trace "fetchurl args, here's hello: ${self.hello}"
# We override fetchurl here, so `super.fetchurl`
super.fetchurl args;
}
self: super: {
# Super because we override `unixtools`
unixtools = super.unixtools // {
# We override `hostname`, so `super`
hostname = super.unixtools.hostname.overrideAttrs (old: {
# old here is effectively also from super!
name = "my-${old.name}";
# We don't override `name` here, so `self`
DERIVATION_NAME = self.unixtools.hostname.name;
});
};
}
self: super: {
# `self` because we don't override `callPackage`
myPackage = self.callPackage ./some/file {
src = self.fetchurl { ... };
};
# `super` because we override `callPackage`
callPackage = super.callPackage;
# `super` because we override lib
lib = super.lib.extend (libself: libsuper: {
# Also `super` because we override `lib.trivial`
trivial = libsuper.trivial // {
# `self` because we don't override `warn`
id = libself.warn "lib.id accessed"
# `super` because we override `lib.trivial.id`
libsuper.trivial.id;
});
}
I generally agree with what @Infinisil said. In practice I just default to self unless I have an explicit reason to be using super (e.g. overriding something).