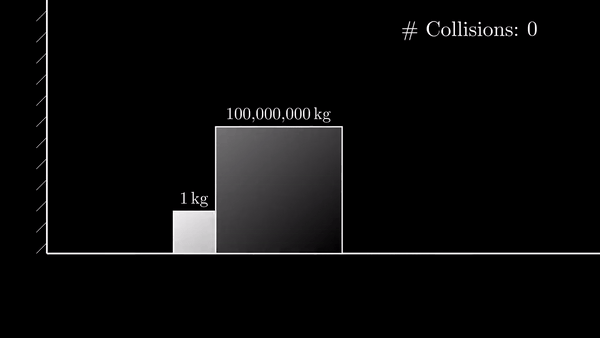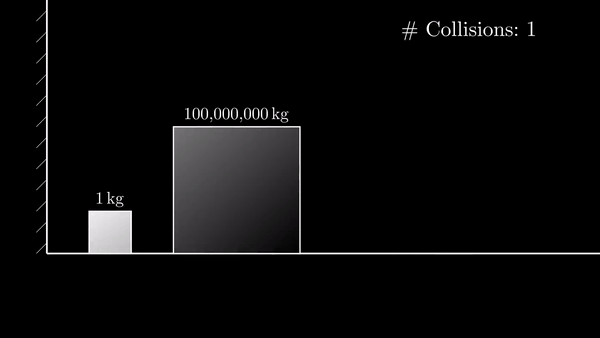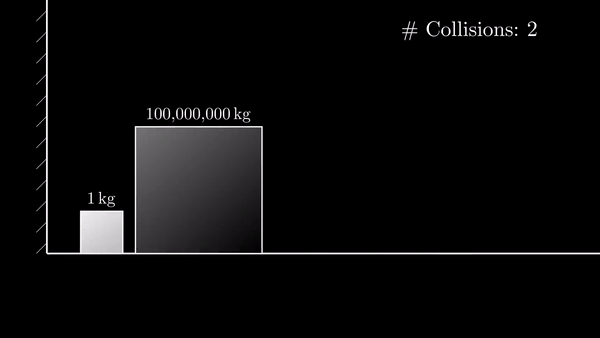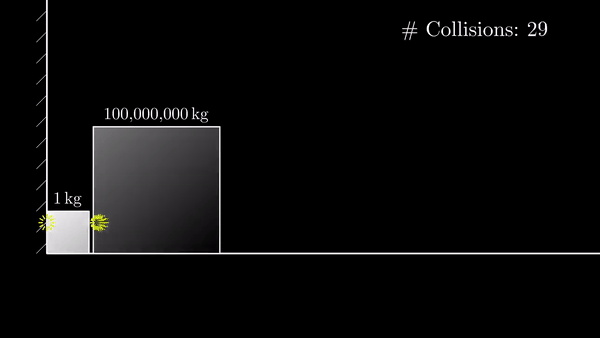How many combinations of waves and package versions are going to be build?
What do we do with packages that cause mass rebuilds, release very often und often
break stuff like hypothesis which releases at least once a week and rebuilds almost everything in python packages?
Thanks, those are really important problems to address, the last one especially.
@-everyone, while Sandro started these, I hope others will follow up on them
I’ll add to the question list too: how should we handle security patches to root packages?
Some visual references of whats in my head when writing the answers:
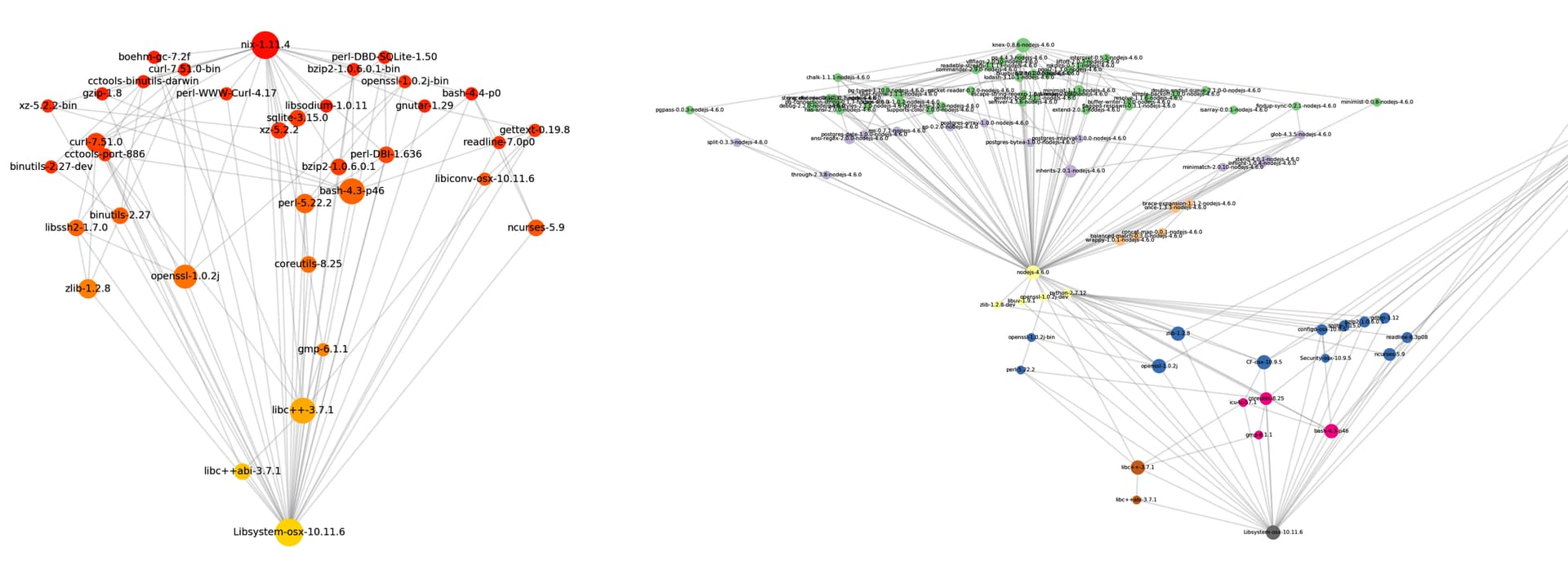
If we look at nixpkgs as trees (roots are at the bottom, image from nix-visualize)
Waves start at some root node, and iteratively expand towards all leaf-nodes.
Major wave: wave-1, O(n) * O(minor-wave)
i=0, updates the bottom yellow node, then starts a minor wave at that node (and waits on it)
i=1, updates the slightly-less yellow node, then starts a minor wave at that node
Minor waves: O(n), n= number of downstream packages
given a root node like zlib (orange, left side)
i=1, zlib is built and tested
i=2, libssh2 (nearest downstream) is built and tested
…
i=?, nix is tested
(no more leaf nodes: end)
This ends up a little bit like this animation, big block = major wave, small block = minor wave
the idea: as big wave progresses, the small waves get smaller and smaller
Q&A
When do major waves start?
It’s a hand-picked decision; Wave-X could be started whenever its realistic/desirable to have a new version of a root package, like a major release of llvm.
When do minor waves start? as soon as the previous minor wave is finished.
(having an wave-X-2pre is fine too if the previous minor wave hasn’t finished)
What goes onto a wave when it started?
This is definitely something I should’ve been more clear about, the “glibc, clang, (etc)” was very vague.
There’s nothing stopping wave-X-1 from updating multiple packages.
Ideally a minor wave would update a group of packages that are either
1: packages that are hyper-related
like deno’s rust crates; deno-dev, deno-core, deno-ops, deno-ast (which import eachother).
or 2: packages with already-upgraded upstreams
So hypothesis would need to be upgraded on a wave before numpy, and numpy on a wave before torch. But torch and pyyaml could probably be upgraded on the same minor wave
Hyper related groups need to be hand crafted, which I imagine is what would be done for heavyweights like llvm, clang, glibc.
The already-upgraded upstreams be automated, and better yet, their tests for these could safely be run in parallel.
What do we do with packages that cause mass rebuilds and release often?
Torch represents this kind of package (or at least I meant for it to)
We know rebuilding/testing on every torch bump is entirely impractical
So, looking 3 pictures up (the Torch vs Nixpkgs one)
Take a look at the middle of that orange line in the diagram: the torch 1.10.2 release
Its not used by any nix-wave; it was never built on nixpkgs or integration tested.
That was made to represent torch updating too fast; nix had to skip torch versions.
Replace torch with llvm, gcc, glibc, openssl and its the same story. The world can’t be rebuilt every time they’re bumped, so (to keep an all-green status) versions are inevitably skipped.
The current Nixpkgs is either similar, or must not be all-green.
When do major waves stop?
Its basically irrelevent, but it would stop by simply running out of downstream packages to update: when every package was updated exactly once.
When do minor waves stop?
Its when all tests for downstream packages are resolved as pass/wont-fix/cant-fix
I’m sure this can be fudged/bent a bit, similar to how replace-dependency gets around the rules
Once a package is updated+rebuilt, its not touched again for the rest of the major-wave
So, to minimize build time, we would want lock-in super heavyweights first
This is why the first 10 minor waves could take longer to test than the next 100 or 1,000
=> wave-X-1 intentionally rebuilds the world (if we’re updating llvm, and we guarentee all-green packages, world-rebuilding seems necessary)
=> wave-X-2 is (approximately) the-world minus packages upgraded in wave-X-1
=> etc
How many combinations of waves and package versions are going to be build?
I’m not exactly sure what this is asking. If this is related to what @milahu brought up, the tldr is probably use whatever current method nixpkgs uses (multiversion), but I’m still working on a full response about that.
How should we handle security patches to foundational packages?
Lets say nixpkgs was working on wave-2-14, meaning openssl was already upgraded and locked-in.
But then a major vulnerability was found in that version of openssl.
There’s at least a few options:
1: Use an existing method like replace-dependency and make all later waves just have the fix without fully testing.
(probably good for small patches)
2: It could be patched on wave-2-14, and the world could be rebuilt
(probably good for medium/big patches that could break stuff)
3: The current major wave is duplicated (including minor waves), but minor waves are marked as unfinished. This way people can use the patch while waiting on tests to catch up.
(probably good for security fixes that require major version updates)
4: Individual environments/users use overrides and pull from the bleeding-edge of the openssl repo
(probably good for 0-day vulns)
Perhaps you meant to say that it defeats the point of NixOS’s shared binary cache.
Overlays are the reason why I use nixpkgs.
PS, this thread could also be titled “Python’s ecosystem is not sustainable”. I am very grateful to the nixpkgs maintainers who are willing to fight with it so I don’t have to. You guys are heroes.
There’s two other suggestions that can help short term:
As suggested above, add your packages, or major packages that would exercise similar codepaths, to passthru.tests in your major dependencies, especially if that dependency doesn’t have any dependees at all in its tests. This can help highlight when seemly innocuous version bumps affect downstream packages.
Review your package’s dependency closure and see if there’s unused inputs. The fewer transitive dependencies your package has, the less it’s going to be affected by breakages. This will also help the packages you remove: the fewer transitive dependents they have, the smaller the fallout when they break.
These suggestions don’t address the fundamental issues, and I’m not familiar enough with the python / ML ecosystem to tell how effective they are going to be in your situation, but they could help.
Incidentally does anyone know if there’s plans to automate / bolster those package break notifications? I use a lot of niche packages / lower tier platforms that shouldn’t block PRs being merged, but I would love to be notified when a PR breaks them so I can fix them immediately instead of only finding out when I try to update my pins.
I do genuinely appreciate this suggestion from yourself and @bjornfor. It’s not something that I had considered previously. But it also is exactly the kind of thing that should be covered by nixpkgs-review/CI anyhow… Part of being a responsible committer is testing the downstream effects of your changes before merging.
It may be the only practical solution atm, but it just feels a bit more like a band-aid than a systemic fix IMHO.
Then I don’t have any other idea than massively reducing the size of pythonPackages.
None that I know off but if we don’t do that right a temporary build failure of a core package could send 1000s of emails.
That works for packages with less then a few hundred reverse dependencies, butnotforpackageswithsometimesthousandsofreversedependencies .
If a core package like requests gets updated we carefully read the changelog for major breaking changes and if there are none staging gets targeted and we hope for the best. There is no other liable way to get this done in a meaningful amount of time. We just cannot guarantee that everything down the entire dependency chain will 100% continue to function. Something 20 packages down the stream can always pin requests for no good reason and break.
Also if we would enforce this no one would willingly maintain any package that has more than a few hundred reverse dependency. In addition to that most maintainers don’t “agree” to the reverse dependencies. The package just gets used and with one commit you can suddenly become responsible for 5000 packages if some other deeply integrated package starts to depend on your package.
I don’t see how a merge train would solve our problems. The typical PR to master is mostly unrelated to the ones that are merged next to it. The chance of breakage there is (very) low. A merge train for those PRs would mostly excercise ofborg and GitHub actions. And it wouldn’t solve the problems you described in this post.
The typical PR to staging on the other hand rebuilds over 2500 (5000) packages. I don’t think it is realistic or feasible to rebuild all changed packages with every PR to staging. If we use the current CI system then breakages would only be discovered by later PRs and the big rebuild would need to be grouped at the start. Also not really a good solution. And right now we do one big PR with hundreds of commits which also wouldn’t work to well.
One takeaway we could do is that for python-updates branches all packages that where touched would need to build. I think that is a realistic target.
So what am I missing? Should we rebuild every changed package with every commit/PR?