What if we can have our cake and eat it too. Or in this case; modularize nixpkgs without actually splitting up nixpkgs.
I do reinforcement learning research, and a key lesson is when two agents/actors are evolving simultaneously; neither agent can learn well. As agent#1 learns something, agent#2 “evolves” and breaks/invalidates what agent#1 just learned. But if they take turns, they can actually learn quickly and converge.
We’ve got that same situation here:
- nixpkgs unstable is changing; breaking torch (or whatever package)
- and torch is changing; breaking stuff in the latest nixpkgs unstable
Even if we cleverly reduce the number of inter-dependencies, it’s not going to categorically change this problem. Upstream/downstream dependencies are branching; O(b^n) even if we change b or n, it’s still an exponential equation and the inputs get bigger every year.
Goals
I can see your point now (@many-people) about how both a monorepo and fewer breakages are important.
We want:
- intercompatible (all green) packages
- maintainable, localized, latest, updates
Fundamental limitations
Nixpkgs unstable (or staging) can not be both all-green AND be the source of the latest versions of everything. There’s not enough compute power in the world to recursively run all the tests on every version bump. So let nixpkgs handle our #1 (intercompatiblity) and not worry about having the latest of literally everything.
On the flip side (the title of this thread) package maintainers can not update their package every time a dependency changes. There’s not enough developer free time in the world to check every upstream change and every downstream consequence. So let individual packages handle our #2 desire; staying up to date and maintainable and not worry about upstream changes, or downstream consequences.
Eating & Having Cake
So let’s consider this; a mono repo and multi repo, treating them like the two-actor coordination problem at the begining.
The multi-repo:
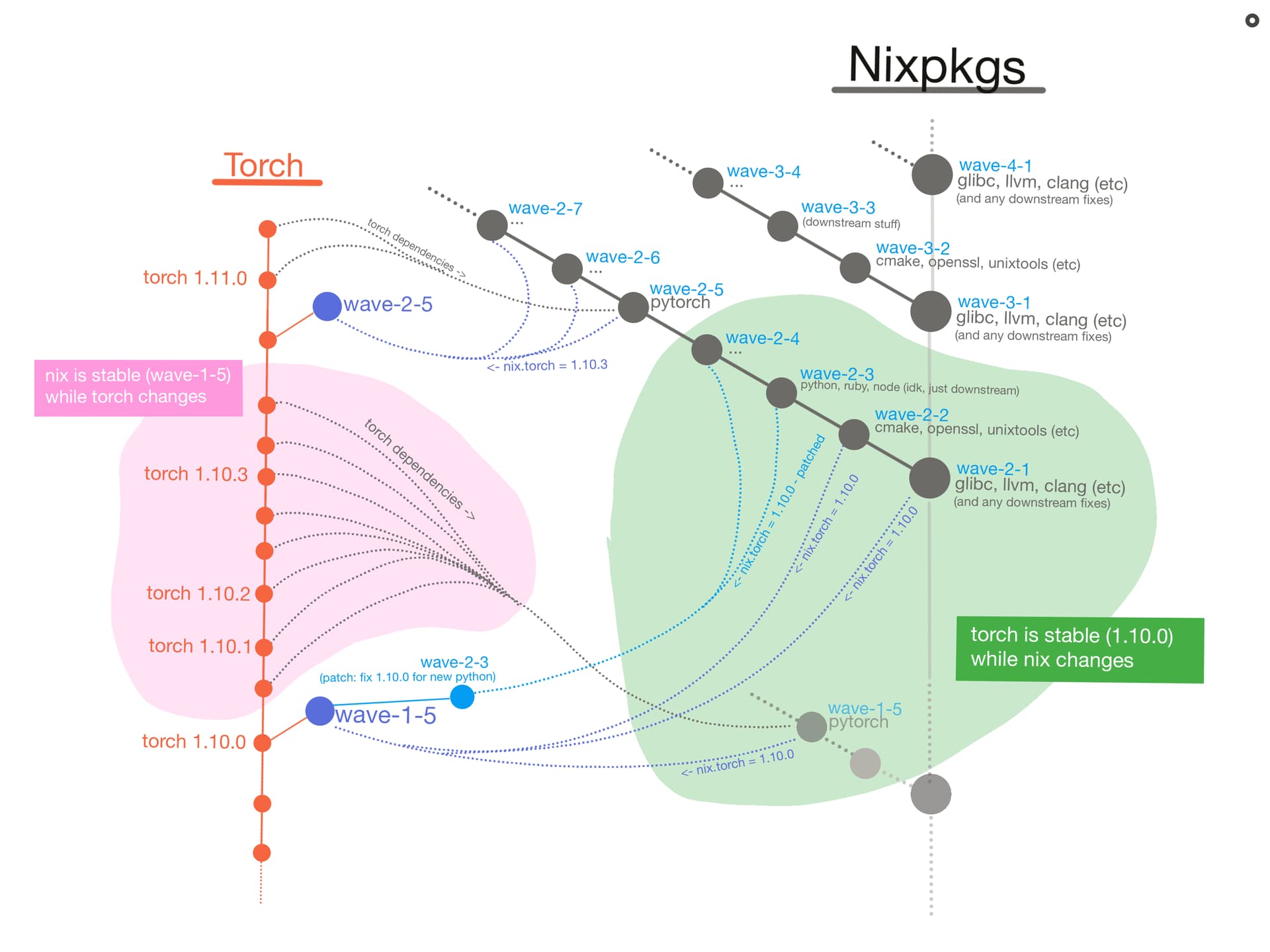
- Assumption: Let’s say the torch (or whatever) maintainer treats nixpkgs as frozen by pinning to a specific nixpkg commit (like the 21.11 release).
- Updates: Now that nixpkgs is not changing, it becomes realistic for a maintainer to attempt getting new versions of torch working. The ground is no longer collapsing from under them.
- Flexibility: However, whenever there is a problem; like if torch needs a new version of GCC, the maintainer has the flexibility to unpin and move up and down the nixpkg timeline (like pinning to the 22.05-pre release) to make this version of torch work.
- Testing: The torch maintainer effectively runs unit tests; only testing torch, without worrying about downstream breakages or the upstream daily nixpkg-unstable changes.
The mono-repo:
- Assumption: On the flip side, nixpkgs can assume that torch is stable by pinning to a version of torch (like the 1.11.0 release), and using overlays to make torch use the latest nixpkgs. This could, but doesn’t have to be done with submodules (submodules could protect against breakages from a multi-repo suddenly changing its url)
- Updates: Just like the multi-repo, the “torch is stable” assumption let’s nixpkgs start upgrading itself without the ground turning into liquid. Instead of packages updating randomly, imagine a Nixpkg upgrade as wave. It begins with bottom/foundational-packages like glibc or openssl. We update glibc, if nothing breaks then create a git tag “wave-1.1” . Then update cmake, if that doesn’t break anything downstream, we finalize a “wave-1.2” tag. Once a tag is finalized, it indicates an all-green set of packages. Eventually it’s torch’s turn to be updated and checked as part of wave-1. But only after torch’s dependencies are all-green.
- Flexibility: Just like the multi-repo, once there is a problem, like glibc breaking downstream stuff, nixpkgs has the flexibility to pick any commit from a package timeline. So if glibc breaks torch, maybe the torch repo already has a fix waiting (torch has been updating itself independently). Ask torch for a “wave-1.1” version, or try the latest stable torch release. If torch is still broken, keep running tests, and file an issue/PR on the torch repo requesting “wave-1.1” support. Only once torch, and the other downstream stuff is fixed, can the wave-1.1 (glibc) be finalized.
- Testing: Even if a minor wave is held-up by a broken package like torch, that doesn’t mean the next major wave can’t start. Wave-2.1 starts as soon as a new glibc or other foundation package is available. All waves are progressively becoming “more green” until they’re finished. A mature wave, even if unfinished, would be pretty stable in theory. E.g. we can each customize how much stability to sacrifice in exchange for cutting-edge-ness. The monorepo acts like one giant integration test that takes months to complete; because an unfinished wave necessarily means something is either broken or untested (unstable). Waves (minor number) could be as small as a single gcc update, assuming that the update breaks literally 0 downstream packages.
This can also be done in hierarchy, with each python package having a mini-repo, and pythonPackages being a monorepo, with nixpkgs using pythonPackages instead of individual packages.
Result
We could get bleeding-edge versions of any individual package, since the package would be using an all-green or mostly-green foundation (pretty stable for bleeding edge). The caveat is if you need multiple bleeding edge packages; they might not play nice together. But if you need everything to play nice together (and don’t want to fix bleeding edge packages yourself) then the only solution is to use the most recent all-green set of packages (which inherently takes a long time to curate and won’t be bleeding-edge).
We can’t magically keep it all green and all bleeding-edge.