Why did I build it?
I got tired of having to always use 2 different tools for bootstrapping and subsequent deployments. And most deployment tools required me to modify the flake to use them. And most of all, all tools hide what is running underneath, making it hard to debug and see where things failed.
Panix is a TUI, build for the next generation of deployments.
Project is part of my masters thesis (also the reason why it is a bit overengineered), so it would mean a lot if you would take it for a spin and comment your experience.
Generated? If you mean LLMs, it is AI assisted: OpenCode: GLM 5.1
If you are curious of the exact setup I use, it is available on mihakrumpestar/infrastructure@9f776bf/modules/home/llm.
For the record: I inspect, edit, correct, verify and push all code by myself, you can verify it by looking at commit history.
The tui (especially the concurrency / multi-flake features), albeit a bit flashy and busy to me, seems really useful for bigger fleets! Congrats on making a master thesis out of this! I’ll give it a shot.
I am however not a big fan of how you have to write a (big) YAML manifest for the tool. To me a simple list of flakes should be able to suffice as far as configuration goes. Further customization (like ssh hostname/username) should probably belong in the actual nixosConfigurations.* config, or a panix flake output (like how colmena does it), so that the flakes that the panix configuration points to can have their own authority of how they should be deployed.
Panix is fundamentally different how it treats nixosConfigurationsthan other tools. In Panix, nixosConfiguration and machine are 2 separate entities, you can deploy a single nixosConfiguration to multiple machines. All other tools threat nixosConfiguration strictly as a machine. Using purely nix would technically be possible, but with separation, it allows more flexibility, like bootstrapping + continues deployments.
This does introduce a lot more complexity for the application, but it is almost completely transparent to the operator/deployer.
Panix was designed not to interfere with your nix/flake configuration at all.
I wanted to allow users to bootstrap and continuously deploy with the least resistance and technical difficulty. Currently, to do that you have to use at least 2 completely different tools, with 2 completely different scopes.
One of the reasons (in my opinion) that NixOS does not have that many users is simply due to the fact the bootstrap and deployment tools are fragmented and don’t compliment/work together. Panix was build to close that gap.
As for the yaml configuration, it has templating with env vars support, and the CLI also has additional subcommands to evaluate it and preview the finalized configuration.
While I did consider and tested using nix as configuration instead of yaml, there simply does not seem to be enough support for it to be used with validating schema, to provide on the fly validation and autocomplete like yaml does.
Huh. I guess so… FWIW nixd can autocomplete NixOS options and such but I have no idea how to get it to work with other module systems (that is, other systems that use lib.evalModules like home-manager)…
Thanks for your clarification. Now it kind-of makes sense to me why I would want the mental overhead of a panix.yaml, it’s however a bit overkill for my 3-ish machines, but alright
Speaking of HM, does it support activating arbitrary profiles like deploy-rs does? (relevant deploy-rs library function) because then I’d be able to move from it entirely (I like your UI/UX way more ).
clarification/rant
I activate my `nixvim` and `home-manager` config seperately because of the eval/build times and flexibility (and seperation, in the case of `home-manager` some setups rely on the host's NixOS config to make decisions on what HM should do)...
No, it does not, only system profiles are supported.
Panix is primarily designed to deploy full systems. If using arbitrary profiles, you would have to specify the profile every time for each machine (or it would at least have to be specified extra in config), and that does not scale in a fleet.
You know what, you’re right! I’ve found that the defaults are sensible enough that I can, for my simple single-flake, one-host-per-config needs, just do this:
YAML config actually allows without {} as value, just keys are enough.
I also realized that the examples I have given were not most intuitive, so I rewrote/updated them. Hopefully they did not discourage too many people from trying Panix out.
My biggest problem with the readme (but that’s probably because it’s a technically interesting feature) is that the first panix.yaml example you see is the one about Hierarchical Configuration Inheritance, which might be overwhelming at first if you don’t even know what a minimal panix.yaml can look like… (and that’s only after scrolling past a big section that explains the phases model)
In a readme, it is (I think) more appropriate to have features at top, which is a (as you noted) a problem if the reader did not take a look at the main content that is later. While I wanted to pack everything into a single markdown file, it may be just too overwhelming for all the features the TUI has.
Should I have a full wiki website to first do the introduction and then features (makes it more structured, but maybe overkill)? Or should I change the readme structure itself (tho I don’t know how I could improve it more than it is already)?
oh I so wait for it to mature even more
Newb myself, but have been looking around through colmena, deploay-rs, nixops etc, this indeed seems most complete right now.
I’m curious about bootstrapping phase, Idk how exactly nixos-anywhere works exactly, but did you have to essentially recreate similar process? Just curious how it compares
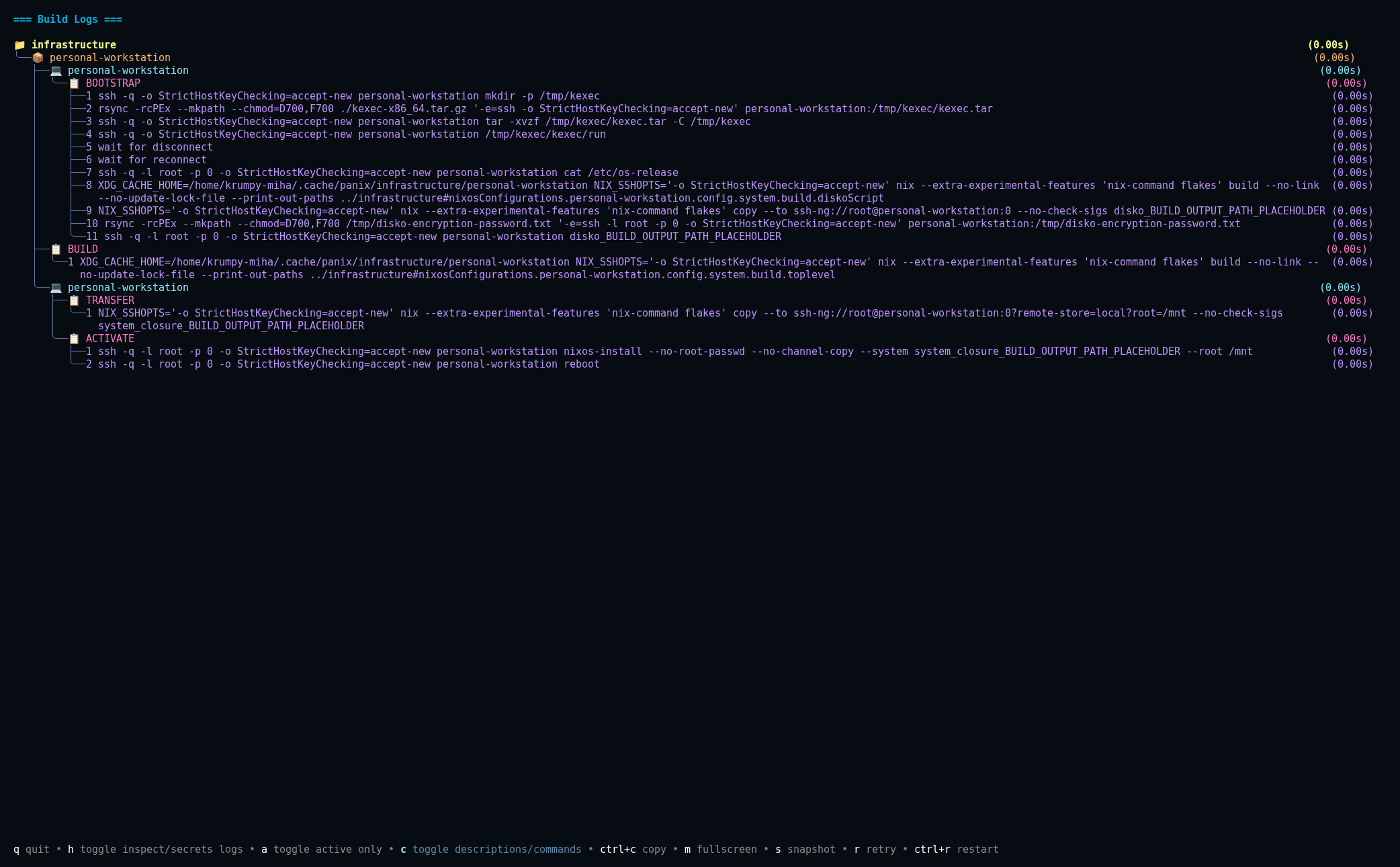
Yes, I tried recreating a minimal requirement of what nixos-anywhere is doing, then with trial and error, test and fix it until it was reproducable on actual hardware and actual Arch live ISO.
One thing that is different is where the kexec gets copied. In nixos-anywhere I think it goes in /home, but on Arch live ISO root partition has like 200MB (or something) space, therefore kexec (of 700MB) errors on copy, but /tmp is mounted differently (seems to be using “tmpfs”, haven’t checked exactly) so Panix uses that, instead of what nixos-anywhere uses.
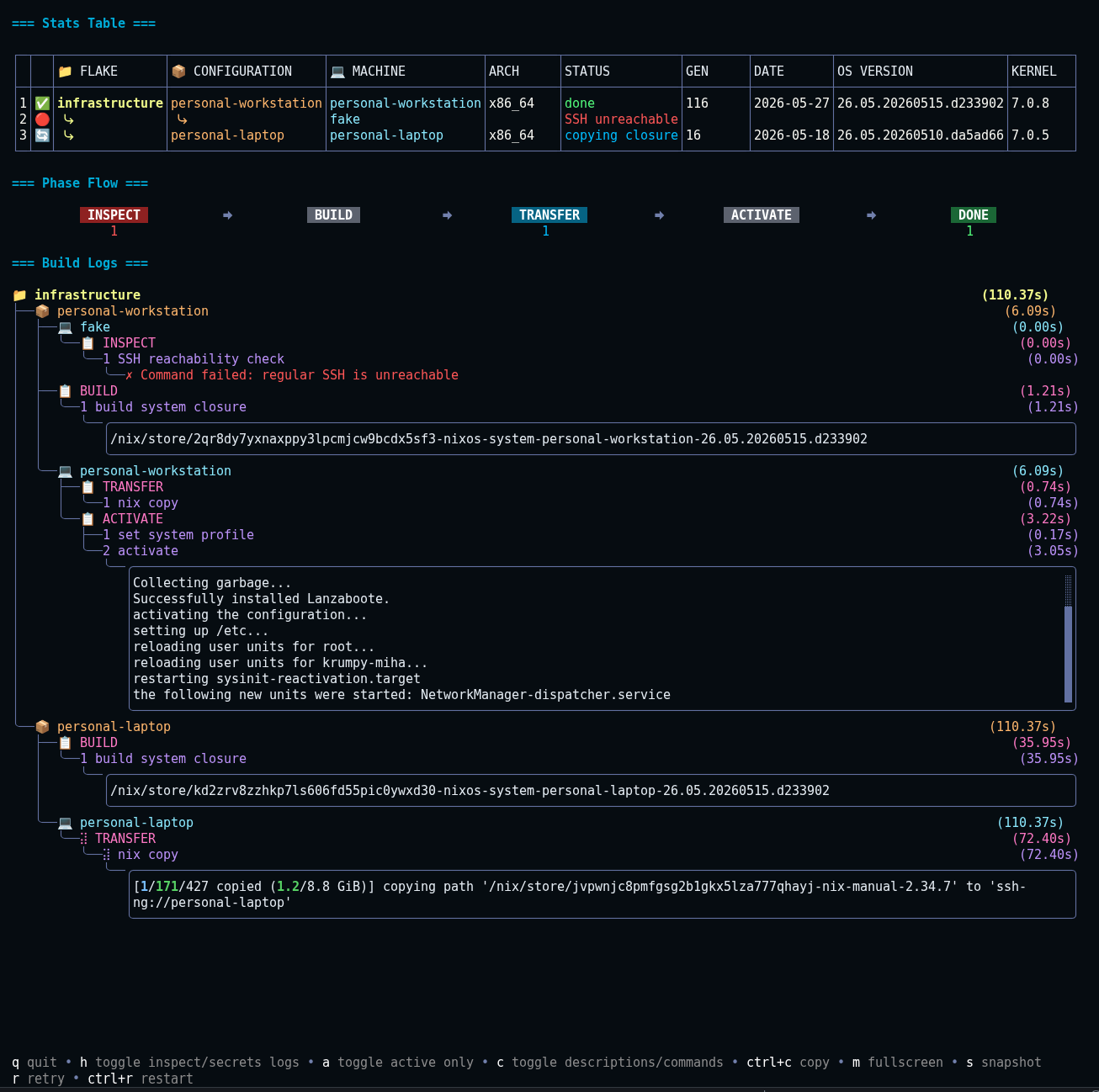
When you run panix deploy --dry-run you press shortcut c: toggle descriptions/commands and bootstrap ssh set, will give you exact commands that would be executed in a real run. Here is an example for my personal-workstation:
TBH I’m still not sure about why it’s better to split flake and deploy config. The main argument “keep it separated for simplicity” is almost moot if one (is able to) write a multi-system flake?
Also, with the growing popularity of dendritic, it’s a one-line empty attribute per host away to have a default deploy attribute automatically output that can be used by the tool and can be customized either inside or outside the host config by specific (merged) attributes. (I’m using this with deploy-rs via denful/den since recently). Maybe it’s possible to satisfy both use cases by (initially) making a generator that creates the yaml from the flake, and optionally integrating it as a first-class use case?
As an idea for extending: especially with the TUI experience it would be cool if one could mark “sub-configurations” under a nixosConfiguration output, e.g. standalone HM configs, for simultaneous deployment
What is the use case for “multiple targets for the same nixosConfiguration”? It will be problematic because of the networking.hostName collision?