Hello!
I have a dedicated server (from Scaleway) on which I installed NixOS many years ago.
Yesterday, I upgraded NixOS from 22.11 to 23.05 and rebooted.
As the server was not getting back up, I noticed that the init process was not found which resulted in a kernel panic:
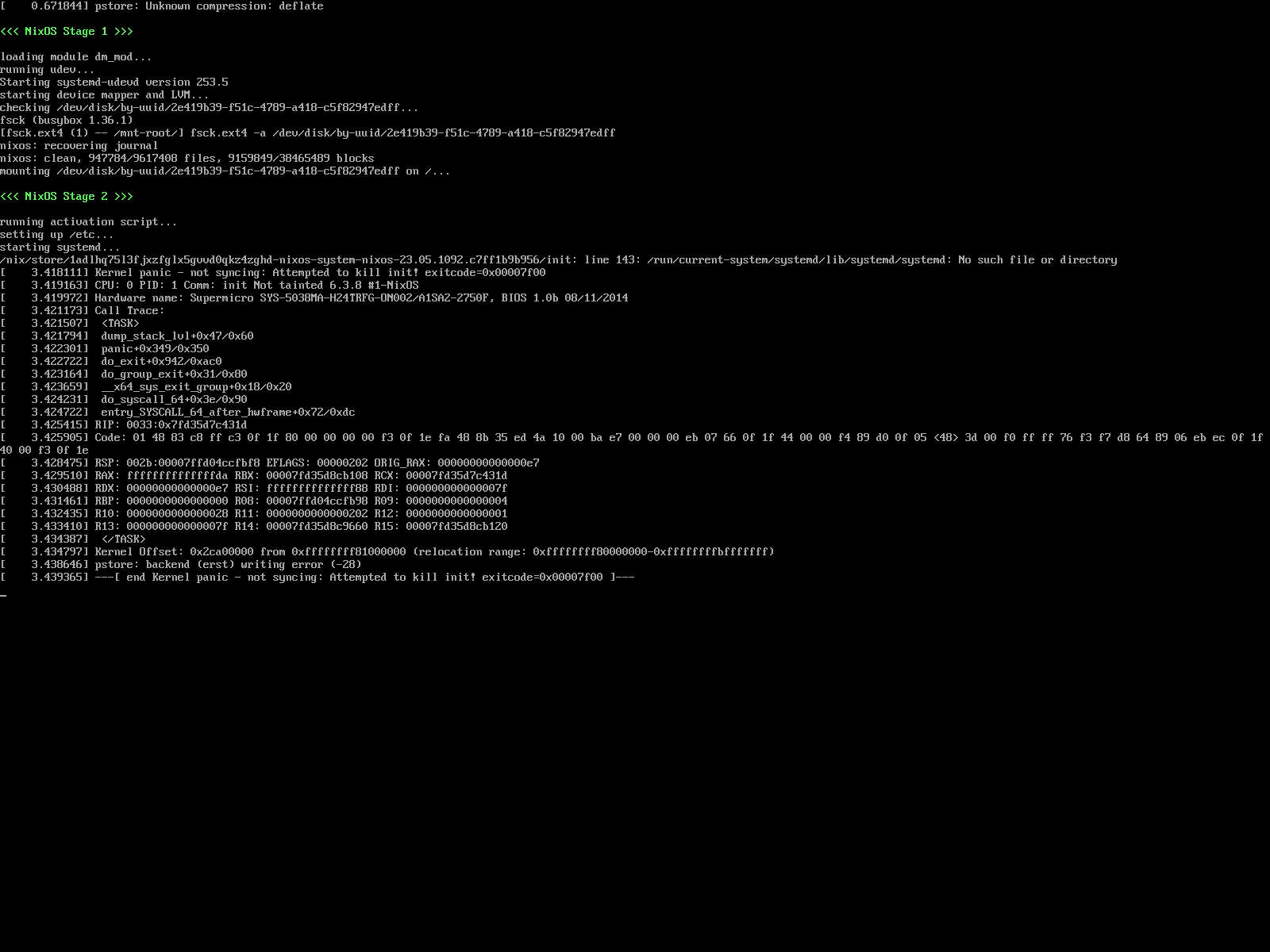
I rebooted in rescue mode, used nixos-enter to chroot into my system and tried to investigate/fix things.
I noticed that the /run/current-system symlink was not there, which breaks a lot of stuff.
This might be because I was in a chroot (so systemd was not up) but I believe this is also the case when booting normally.
After long hours, I managed to mitigate the issue by adding the following in /etc/nixos/configuration.nix:
system.activationScripts = {
fixboot.text = ''
ln -sfn "$(readlink -f "$systemConfig")" /run/current-system
'';
};
This is basically the same command that runs at the end of the activation script, but sooner.
For the record, here is the end of my generated activation script (/run/current-system/activate):
# Make this configuration the current configuration.
# The readlink is there to ensure that when $systemConfig = /system
# (which is a symlink to the store), /run/current-system is still
# used as a garbage collection root.
ln -sfn "$(readlink -f "$systemConfig")" /run/current-system
# Prevent the current configuration from being garbage-collected.
mkdir -p /nix/var/nix/gcroots
ln -sfn /run/current-system /nix/var/nix/gcroots/current-system
exit $_status
This fixes the issue and allows my server to boot normally, but I really don’t understand why I need to do this.
The issue is clearly caused by /run/current-system not being there when systemd is supposed to run and take over, but I have no idea why.
Maybe the normal symlink command does not run?
Maybe the symlink is deleted before the end of the init script?
Also, this may not be related to the upgrade of NixOS from 22.11 to 23.05 because I hadn’t rebooted my server for a while (it is possible that I didn’t reboot after previous upgrades); so maybe something broke a while ago ![]() .
.
Does anyone have any idea of what could be the cause or how to further investigate?
For the record, here is how I chroot from rescue mode (it was not easy to figure this out):
- reboot the server in rescue mode using Scaleway’s dashboard (an Ubuntu rescue image is selected)
- SSH into it
-
sudo dpkg-reconfigure locales(add232. fr_FR ISO-8859-1and233. fr_FR.UTF-8 UTF-8; for some reasons I need an ISO-8859-1 locale to be able to mount my /boot partition) export LANG=POSIXexport LC_ALL=POSIXbash <(curl -L https://nixos.org/nix/install). /home/david/.nix-profile/etc/profile.d/nix.sh-
nix-env -f '<nixpkgs>' -iA nixos-install-tools(to havenixos-enter) sudo mount /dev/sda9 /mntsudo mount /dev/sda1 /mnt/bootsudo $(which nixos-enter)-
PATH=$PATH:/nix/var/nix/profiles/system/sw/bin/(I need this because at this point there is no/run/current-systemso$PATHis quite empty and I cannot run any command) ln -sfn "$(readlink -f /nix/var/nix/profiles/system)" /run/current-systemsu david- at this point I can run most commands as usual (if they don’t rely on systemd) which allows me to run
nixos-rebuild boot