I would like to be notified (through my local ntfy instance) if this service exits with some errors. However, I would like to avoid bloating my system with other apps, like prometheus & company.
I am still quite noob with Nixos but digging through various topics I came up with the following, which I don’t know if it makes sense/will work:
Here’s a similar approach that pings a private healthchecks.io instance when backup starts, succeeds or fails. Should be trivially adaptable to ntfy.sh. As a bonus - it sends journald extract of a failure.
I pair it with prometheus and friends for a more comprehensive view, but that’s optional.
I had seen that git but for me (who I am the furthest from being a programmer) it is quite difficult to adjust that code for my need. I was hoping to find a piece of code that was simpler for me to understand and adapt.
Don’t sell yourself short :). You had the right idea in the first post.
Fundamentally what’s happening here:
There’s a service which may succeed or fail (btrfs-scrub)
Failure is signaled to systemd. Systemd usually relies on the process exit code to determine if the service finished OK (0 OK, otherwise not OK)
Systemd can trigger another service depending on the outcome of the service (systemd.services.btrfs-scrub.unitConfig.OnFailure or OnSuccess)
aside: in my case I am triggering the notification service when the original service starts (that’s the Wants part) and upon exit. This way I can later see if the backups are too slow and get alerted if they just fail.
Systemd services can be templated (by naming them with @ sign). This allows creating services dynamically.
This means that whenever you declare a dependency like systemd.services.btrfs-scrub.unitConfig.OnFailure = ["notify-failure@bar"], when btrfs-scrub fails – systemd will start notify-failure@bar service. The “bar” part will be available to the script of the notify-failure@ service as %i variable.
In your script you are not using that variable (you don’t really have to), but if you would like for the notification message to say “btrfs-scrub exited with errors”, you could use something along the line of:
script = ''${pkgs.curl}/bin/curl -d "%i exited with errors" ntfy.mydomain.com/mytopic'';
I assume that “ntfy.mydomain.com” can be resolved when the script runs.
General note: when invoking curl in non-interactive manner (scripts, etc.) it’s better to have some controls over retries and timeouts to guard against various failures. I am using retries, failing fast on server errors and max time + the fact that healthchecks will alert me if it hasn’t seen success or failure ping.
Thank you for the encouragement and sorry for my late reply. However, I am still puzzled on some aspects and, ultimately, if the code snippet I had in mind in the first message would work.
First, you write:
There’s a service which may succeed or fail (btrfs-scrub)
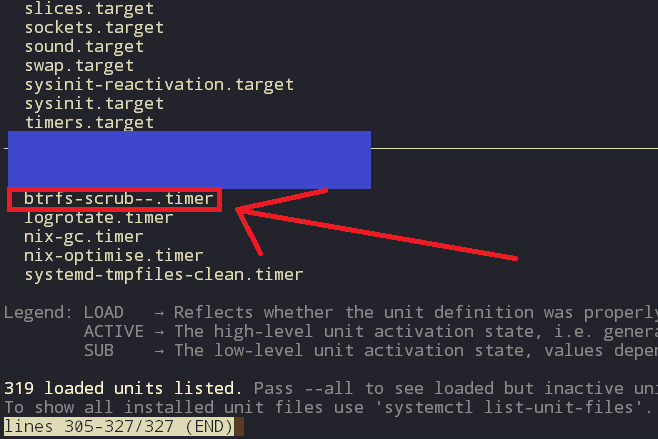
You mention btrfs-scrub (which actually it was me who first mentioned it in my initial post). Nevertheless, I am not really sure that this is how the systemd service is named.
Do you know how can I find out the real name? According to this, I suspect the service name should be something like “btrfs-scrub-/”? Is it true?
On the light of what you wrote, I rewrote the script like the following:
systemd.services.btrfs-scrub-/.unitConfig.onFailure = [ "notify-failure@btrfs-scrub" ];
systemd.services."notify-failure@btrfs-scrub" = {
enable = true;
description = "Failure notification for %i";
script = ''${pkgs.curl}/bin/curl -d \
--fail `#fail fast on server errors` \
--show-error --silent `#show error <=> it fails` \
--max-time 10 \
--retry 3 \
--data "%i exited with errors" ntfy.mydomain.com/mytopic'';
};
Will it work? Is there a way to test it? I don’t want to test my luck that btrfs scrub fails and hope it will work…
Eyeball the nix module code by looking for systemd.services.<srvName>. Works for simple cases. But when paths are involved in systemd names – systemd uses special escaping mechanism (in that nix module it’s utils.escapeSystemdPath, in shell it’s systemd-escape <path>. The name of the service would then be:
{
description = "Sample check flake";
inputs = {
nixpkgs.url = "nixpkgs/nixos-24.05";
home-manager = {
url = "github:nix-community/home-manager/release-24.05";
inputs.nixpkgs.follows = "nixpkgs";
};
};
outputs =
inputs@{ self, nixpkgs, ... }:
let
system = "x86_64-linux";
pkgs = import nixpkgs { inherit system; };
in
{
checks.${system}.test = pkgs.testers.runNixOSTest {
name = "test";
node.specialArgs = {
inherit (self) inputs outputs;
};
nodes.machine1 =
{
pkgs,
config,
lib,
...
}: # { config, pkgs, ... }:
{
# Boilerplate
services.getty.autologinUser = "root";
# btrfs setup
virtualisation.useDefaultFilesystems = false;
virtualisation.rootDevice = "/dev/vda";
boot.initrd.postDeviceCommands = ''
${pkgs.btrfs-progs}/bin/mkfs.btrfs --label root /dev/vda
'';
virtualisation.fileSystems = {
"/" = {
device = "/dev/disk/by-label/root";
fsType = "btrfs";
};
};
# Not boilerplate
services.btrfs.autoScrub.enable = true;
environment.systemPackages =
# This trace prints all service attribute names that begin with "btrfs"
builtins.trace (lib.pipe config.systemd.services [
builtins.attrNames
(builtins.filter (lib.hasPrefix "btrfs"))
]) [ ];
};
# If developing a proper test script, see
# https://nixos.org/manual/nixos/stable/#ssec-machine-objects
testScript = "start_all()";
};
};
}
Then eval it to get the actual attribute name:
❯ nix run -L .\#checks.x86_64-linux.test.driverInteractive
trace: [ "btrfs-scrub--" ]
Look for the service in output of systemctl list-units
On the light of what you wrote, I rewrote the script like the following:
This looks good at a glance. (except for the service name) You don’t need to test it against real btrfs-scrub and hope that it fails. You can construct an always failing service and run it by hand. Something like:
systemctl start always-fails should trigger the notification.
Don’t be afraid to experiment. In most cases nix will either refuse to evaluate an incorrect configuration or allow you to roll back to a previous config. Alternatively, use the nixosTest(point 2 above) to create completely ephemeral machines to test things.
Of course, I modified the ntfy domanin with the proper one.
I gave a switch and it built and switched without errors. I then gave sudo systemctl start always-fails but did not get any notification on ntfy. The journal for always-fails gives this:
user@pc ~> sudo journalctl -fu always-fails
Sep 14 10:41:29 server systemd[1]: /etc/systemd/system/always-fails.service:3: Failed to add dependency on notify-failure@btrfs-scrub, ignoring: Invalid argument
Sep 14 10:41:29 server systemd[1]: Started Always fails.
Sep 14 10:41:29 server systemd[1]: always-fails.service: Main process exited, code=exited, status=203/EXEC
Sep 14 10:41:29 server systemd[1]: always-fails.service: Failed with result 'exit-code'.
While giving sudo journalctl -fu "notify-failure@btrfs-scrub" does not come out with anything. It just stays hanging and have to give CTRL+C to terminate the command. Also tried with sudo journalctl -fu notify-failure@btrfs-scrub and sudo journalctl -fu notify-failure with the same result.
Do you know what is the issue? Thank you very much for all your help!
Turns out it should be qualified with a .service explicitly. Here’s the contents of the “test” that work:
{
# Boilerplate
services.getty.autologinUser = "root";
# Not boilerplate
systemd.services."notify-failure@" = {
enable = true;
description = "Failure notification for %i";
# script = ''${pkgs.curl}/bin/curl -d "Autoscrub exited with errors" ntfy.mydomain.com/mytopic'';
# Just log
# One way to pass args, as in @rnhmjoj example
scriptArgs = "%i";
script = "echo 'Hello from notify-service' && echo 'Var value is:' $1";
# Alternative:
# serviceConfig.ExecStart = "/run/current-system/sw/bin/echo %i"; # /run... is an alternative to setting .path on the service. I am just lazy.
};
systemd.services.always-fails = {
description = "Always fails";
serviceConfig.ExecStart = "exit 1";
unitConfig.OnFailure = [ "notify-failure@btrfs-scrub.service" ];
};
};
Here’s the log:
machine1 # [ 10.918271] systemd[1]: Started Always fails.
machine1 # [ 10.933349] systemd[1]: always-fails.service: Main process exited, code=exited, status=203/EXEC
machine1 # [ 10.934299] systemd[1]: always-fails.service: Failed with result 'exit-code'.
machine1 # [ 10.937291] systemd[1]: always-fails.service: Triggering OnFailure= dependencies.
machine1 # [ 10.940255] systemd[1]: Created slice Slice /system/notify-failure.
machine1 # [ 10.946589] systemd[1]: Started Failure notification for btrfs-scrub.
machine1 # [ 10.965154] notify-failure_-start[907]: Hello from notify-service
machine1 # [ 10.966027] notify-failure_-start[907]: Var value is: btrfs-scrub
machine1 # [ 10.967720] systemd[1]: notify-failure@btrfs-scrub.service: Deactivated successfully.
Thank you both! It now works (at least the with the test script ). I will leave the final code here so hopefully it can help someone else or the me of the future:
services.btrfs.autoScrub = {
enable = true;
interval = "weekly";
fileSystems = [ "/" ];
};
systemd.services.btrfs-scrub--.unitConfig.onFailure = [ "notify-failure@btrfs-scrub.service" ];
systemd.services."notify-failure@" = {
enable = true;
description = "Failure notification for %i";
scriptArgs = "%i"; # Content after '@' will be sent as '$1' in the below script
script = ''${pkgs.curl}/bin/curl \
--fail `#fail fast on server errors` \
--show-error --silent `#show error <=> it fails` \
--max-time 10 \
--retry 3 \
--data "$1 exited with errors" ntfy.mydomain.com/failures'';
};
# Systemd service example to try that 'notify-failure@btrfs-scrub' works.
# Give 'sudo systemctl start always-fails' to start it.
systemd.services.always-fails = {
description = "Always fails";
serviceConfig.ExecStart = "exit 1";
unitConfig.OnFailure = [ "notify-failure@btrfs-scrub.service" ];
};